PyTorch CycleGAN
1.0.0
Una implementación de Pytorch limpia y legible de Cyclegan (https://arxiv.org/abs/1703.10593)
El código está destinado a funcionar con Python 3.6.x , no se ha probado con versiones anteriores
Siga las instrucciones en pytorch.org para su configuración actual
Para trazar gráficos de pérdida y dibujar imágenes en una buena vista del navegador web
pip3 install visdom
Primero, deberá descargar y configurar un conjunto de datos. La forma más fácil es usar uno de los conjuntos de datos ya existentes en el repositorio de UC Berkeley:
./download_dataset <dataset_name>
Válido <DataSet_Name> son: Apple2orange, Summer2Winter_Yosemite, Horse2zebra, Monet2Photo, Cezanne2Photo, Ukiyoe2Photo, VanGogh2Photo, Maps, paisajes urbanos, fachadas, iPhone2DSLR_Flower, AE_Photos
Alternativamente, puede crear su propio conjunto de datos configurando la siguiente estructura del directorio:
.
├── datasets
| ├── <dataset_name> # i.e. brucewayne2batman
| | ├── train # Training
| | | ├── A # Contains domain A images (i.e. Bruce Wayne)
| | | └── B # Contains domain B images (i.e. Batman)
| | └── test # Testing
| | | ├── A # Contains domain A images (i.e. Bruce Wayne)
| | | └── B # Contains domain B images (i.e. Batman)
./train --dataroot datasets/<dataset_name>/ --cuda
Este comando comenzará una sesión de capacitación utilizando las imágenes en el directorio de DatarOt/Train con los hiperparámetros que mostraron los mejores resultados según los autores de CycleGan. Eres libre de cambiar esos hiperparámetros, ver ./train --help para una descripción de ellos.
Tanto los pesos de generadores y discriminadores se ahorrarán en el directorio de salida.
Si no posee una GPU, elimine la opción - -Cuda, ¡aunque le aconsejo que obtenga una!
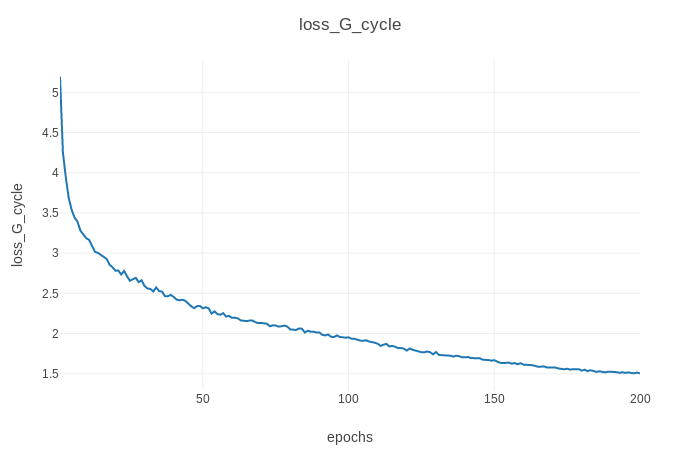
También puede ver el progreso del entrenamiento, así como las imágenes de salida en vivo ejecutando python3 -m visdom en otro terminal y abriendo http: // localhost: 8097/en su navegador web favorito. Esto debería generar el progreso de la pérdida de entrenamiento como se muestra a continuación (parámetros predeterminados, conjunto de datos Horse2zebra):
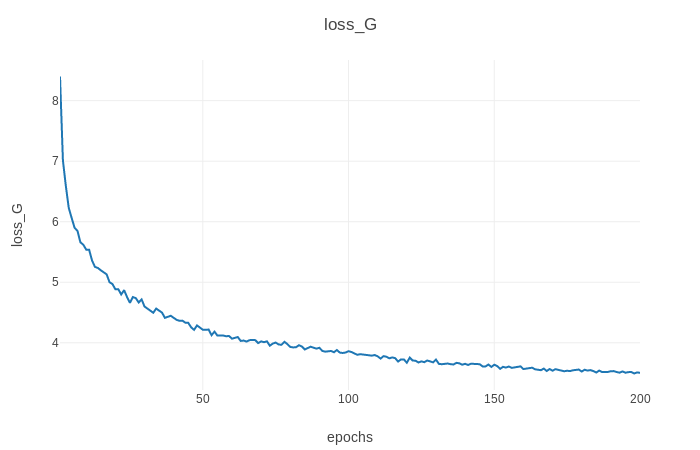
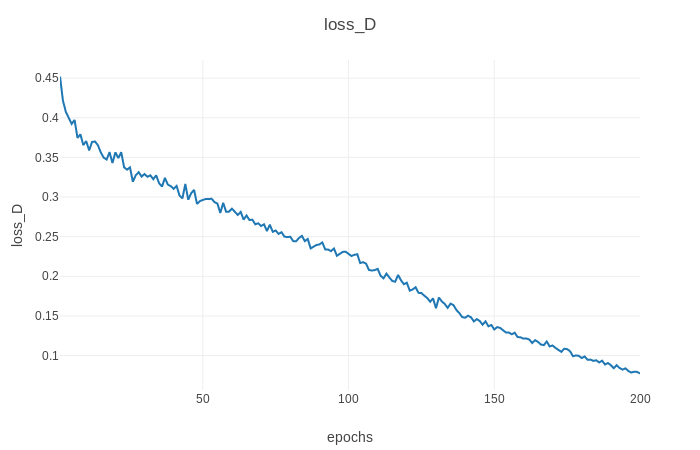
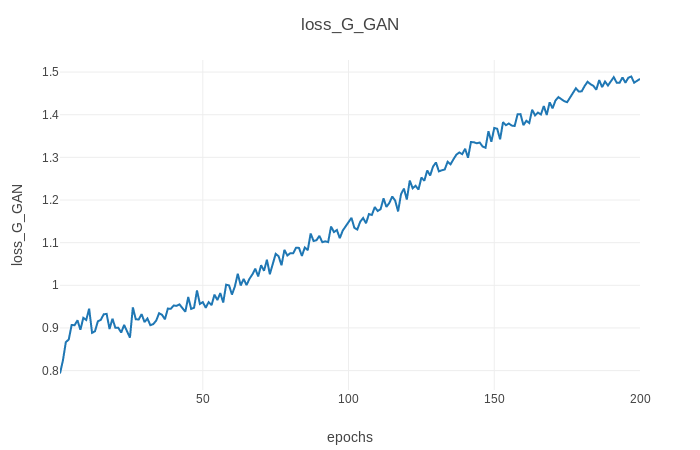
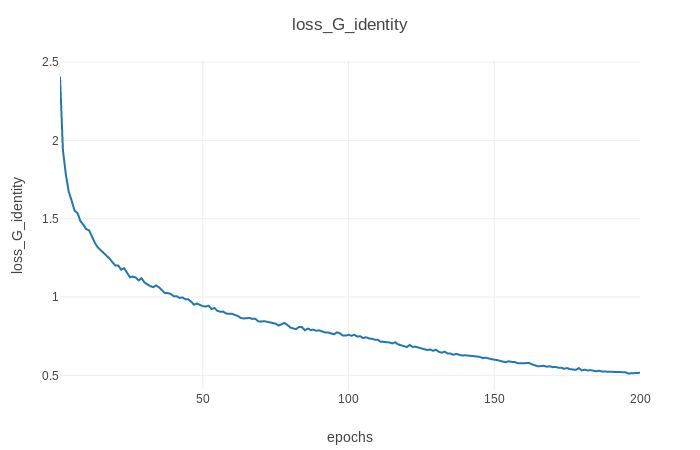
./test --dataroot datasets/<dataset_name>/ --cuda
Este comando tomará las imágenes en el directorio de Datoot/Test , las ejecutará a través de los generadores y guardará la salida en los directorios de salida/A y salida/B . Al igual que con el tren, se pueden ajustar algunos parámetros como los pesos para cargar, ver ./test --help para obtener más información.
Ejemplos de las salidas generadas (parámetros predeterminados, conjunto de datos Horse2zebra):




Este proyecto tiene licencia bajo la licencia GPL V3; consulte el archivo License.MD para más detalles.
El código es básicamente una implementación más limpia y menos oscurecida de Pytorch-Cyclegan-and Pix2pix. Todo el crédito va a los autores de Cyclegan, Zhu, Jun-Yan y Park, Taesung y Isola, Phillip y Efros, Alexei A.


