R-red
- Una implementación de TensorFlow de R-NET: Comprensión de lectura en máquina con redes de autopareje. Este proyecto está especialmente diseñado para el conjunto de datos de escuadrón.
- Si tiene alguna pregunta, comuníquese con Wenxuan Zhou ([email protected]).
Requisitos
Ha habido muchos problemas conocidos causados por el uso de diferentes versiones de software. Consulte sus versiones antes de abrir problemas o enviarme un correo electrónico.
General
- Python> = 3.4
- descomprimir, wget
Paquetes de Python
- tensorflow-gpu> = 1.5.0
- Spacy> = 2.0.0
- TQDM
- ujson
Uso
Para descargar y preprocesar los datos, ejecutar
# download SQuAD and Glove
sh download.sh
# preprocess the data
python config.py --mode prepro
Los hiper parámetros se almacenan en config.py. Para depurar/entrenar/probar el modelo, ejecutar
python config.py --mode debug/train/test
Para obtener el puntaje oficial, correr
python evaluate-v1.1.py ~ /data/squad/dev-v1.1.json log/answer/answer.json
El directorio predeterminado para el archivo de registro de TensorBoard es log/event
Ver lanzamiento para el modelo entrenado.
Implementación detallada
- El artículo original utiliza atención aditiva, que consume mucha memoria. Este proyecto adopta la atención multiplicativa escala presentada en la atención es todo lo que necesita.
- Este proyecto adopta la deserción variacional presentada en una aplicación teóricamente fundamentada de abandono en redes neuronales recurrentes.
- Para resolver el problema de degradación en RNN apilado, las salidas de cada capa se concatenan para producir la salida final.
- Cuando la pérdida en el desarrollo del desarrollo aumenta en un cierto período, la tasa de aprendizaje se reduce a la mitad.
- Durante la predicción, el proyecto adopta el método de búsqueda presentado en la comprensión de la máquina utilizando Match-LSTM y el puntero de respuesta.
- Para abordar el problema de la eficiencia, esta implementación utiliza el método de facturación (aportado por Xiongyifan) y Cudnngru. El método de fútbol puede acelerar el entrenamiento, pero reducirá la puntuación F1 en un 0.3%.
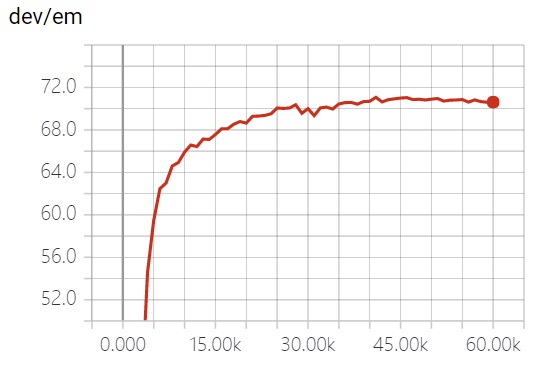
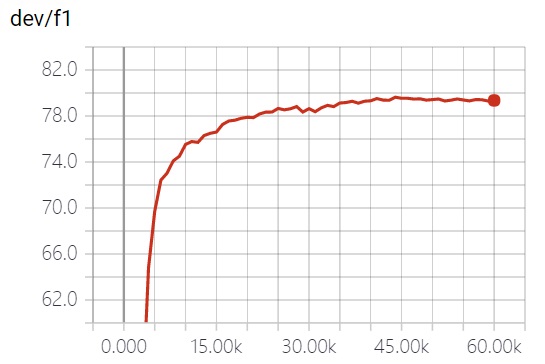
Actuación
Puntaje
| Em | F1 |
|---|
| papel original | 71.1 | 79.5 |
| este proyecto | 71.07 | 79.51 |
Tiempo de entrenamiento (s/it)
| Nativo | Nativo + cubo | Cudnn | Cudnn + cubo |
|---|
| E5-2640 | 6.21 | 3.56 | - | - |
| Titán X | 2.56 | 1.31 | 0.41 | 0.28 |
Extensiones
Estas configuraciones pueden aumentar la puntuación pero no se usan en el modelo por defecto. Puede activar estas configuraciones en config.py .
- Incrustación de personaje de guante previo a la aparición. Contribuido por Yanghanxy.
- Fasttext incrustación. Contribuido por Xiongyifan. Puede aumentar el F1 en un 1% (informado por Xiongyifan).


