efrei m1 jakartaee projet
1.0.0
El Torneo Rolland Garos es un torneo internacional de tenis.
Desarrolle una administración web de partidos en el torneo Rolland Garos.
Papel funcional del proyecto La aplicación debe hacer posible planificar los partidos y el plan en el que los jugadores participarán, qué árbitro lo supervisará. Luego, debe poder informar los resultados del partido (los puntajes de cada equipo). Los visitantes deben poder consultar los resultados de los partidos terminados.
Al llevar a cabo nuestro proyecto, hicimos varios supuestos sobre la operación que imaginamos para nuestra aplicación y para garantizar la consistencia de este último:
Hipótesis 1:
Un organizador se define a sí mismo si los partidos dobles son partidos masculinos, femeninos o mixtos cuando anotó a los jugadores en un partido. Es decir que si anotó en un doble partido, un hombre y una mujer en el mismo equipo, el partido es mixto. Para partidos simples, no es posible que un hombre se enfrente a una mujer, sin embargo, no está prohibido por dobles que un equipo de dos hombres se enfrente a un equipo de dos mujeres.
Hipótesis 2:
Tenemos solo una solicitud para periodistas y organizadores y no dos aplicaciones separadas. Por lo tanto, tenemos una página de inicio, así como una página que le permite ver los partidos terminados, y las otras acciones (como agregar jugadores, planificar partidos, etc.) solo son accesibles después de una conexión (para obtener más información sobre la seguridad utilizada, consulte la parte de seguridad del informe).
Hipótesis 3:
Presumimos que los partidos podrían durar un máximo de 4 horas. Hemos agregado una función que verifica que un curso es gratuito antes de poder seleccionarlo para una nueva coincidencia. Por lo tanto, podemos asegurarnos de que dos juegos diferentes no se puedan jugar al mismo tiempo en el mismo curso. La duración máxima de 4 horas nos permite poner un límite para poder seleccionar un curso, incluso si se planea una coincidencia, pero aún no se termina 4 horas antes del inicio del nuevo partido.
Para llevar a cabo este proyecto, nos organizamos utilizando el método ágil.
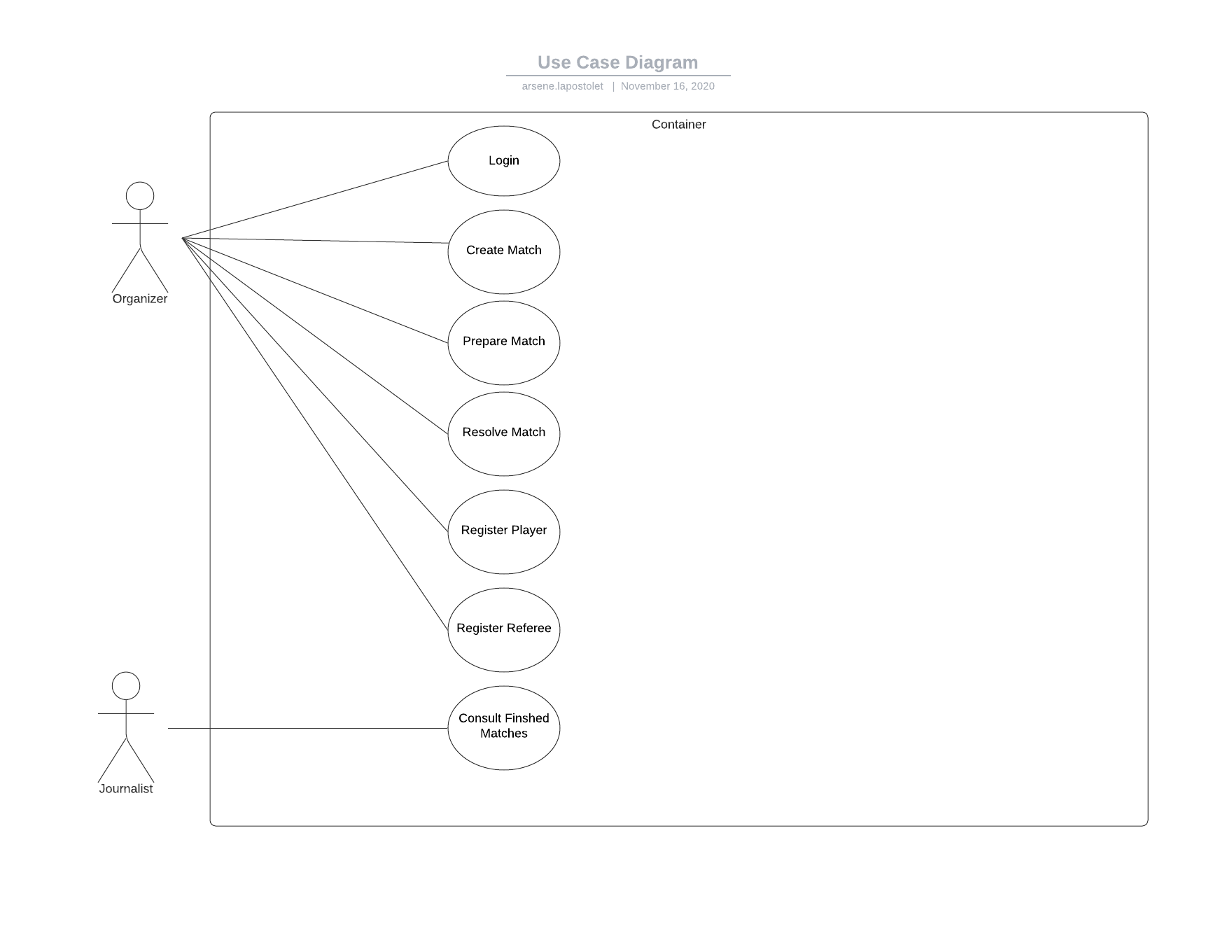
Al comienzo del proyecto, escribimos cuentas de usuario de la siguiente aplicación:
Esto corresponde al siguiente diagrama de casos de uso:
Luego dividimos estas historias de usuarios en tareas de desarrollo.
Cada sesión correspondió a un sprint: hicimos una reunión al comienzo de la sesión para determinar qué tareas deberían ser parte del proyecto. Para facilitar la tarea, utilizamos las herramientas de gestión de proyectos integradas con GitHub: los puntos de venta, el suéter de solicitud y la mesa Kanban.
Las tareas fueron representadas por el resultado, que se puede asignar a un colaborador. El progreso de las tareas fue seguido por tener los puntos de venta en la mesa Kanban. Cuando un empleado había terminado una tarea, creó un suéter de solicitud asociado y lo presentó para una revisión del código.
El flujo de trabajo fue el siguiente:
JSTL: un componente de la plataforma JEE para extender la especificación JSP agregando una biblioteca de balizas para las tareas actuales, como el trabajo en libertad condicional, bucles e internacionalización.
MariaDB : Implémentation Open Source du Système de Gestion de
Base de Données Relationnel MySQL.
Jakartaee: Especificación de código abierto de Java EE. Usamos JSP en particular, los contenedores de servlet, el EJB y JPA.
Bootstrap est un framework CSS permettant de facilement implémenter des styles
prédéfinis
Wildfly (anteriormente JBoss) es un servidor de aplicaciones de código abierto que implementa la especificación Java EE / Jakarta EE.
EJB / Enterprise JavaBeans est une API de composants logiciels coté serveur
permettant d’encapsuler la logique métier des applications d’entreprise.
JPA (Especificación) / Hibernate (Implementación) es un ORM que le permite serializar y Estarializar los objetos Java (entidad EJB) en un sistema de gestión de bases de datos relacionales.
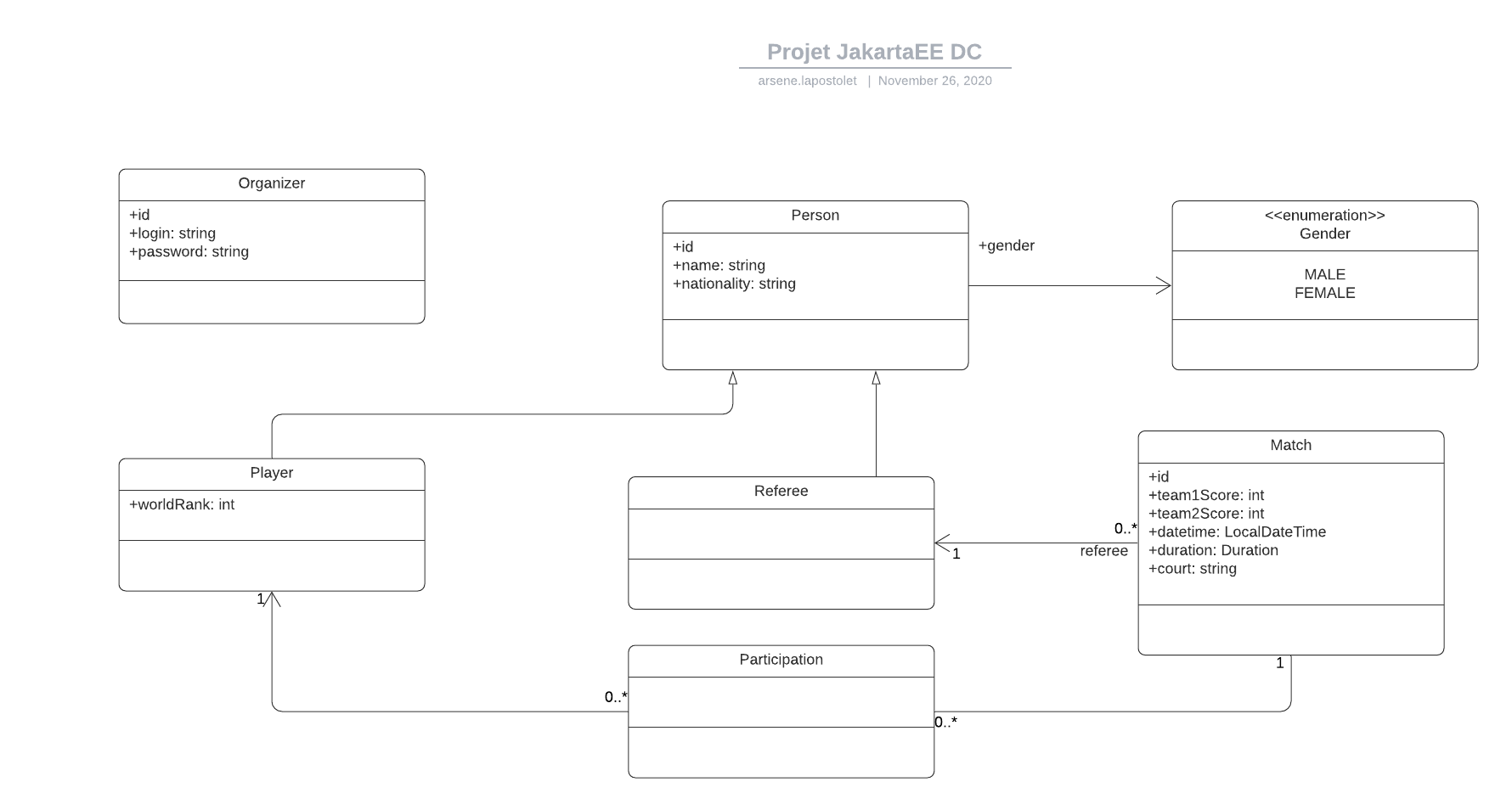
Utilizamos la arquitectura de "arquitectura limpia" llamada SO, también llamada arquitectura de "cebolla", compuesta por diferentes capas, desacopladas entre sí por contratos de servicio descritos por interfaces. Cuando llega una solicitud, primero es procesada por el controlador, para crear objetos a partir de los datos, luego pasa a través de la capa de servicio que contiene la lógica comercial. La capa de servicio requiere la capa de restitorio que contiene interacciones con la base de datos. La capa restitoria utiliza las clases de las entidades del modelo de datos.
En nuestra aplicación nuestra, cada capa corresponde a los siguientes componentes:
Utilizamos la programación de interfaz, así como el mecanismo de inyección de dependencias permitido por las compañías de granos Java para tener un bajo acoplamiento entre los componentes de la aplicación.
Hemos tenido cuidado de no almacenar las contraseñas de los usuarios en la base de datos. Por lo tanto, si este último fuera pirateado, los atacantes no tendrían acceso a las contraseñas. Hemos elegido cortar contraseñas con el algoritmo de hash salado BCrypt, porque es el estándar en el asunto. Para hacer esto, importamos la biblioteca JBCrypt en nuestro proyecto (a través de Maven) que implementa el algoritmo en Java.
En la aplicación, la mayoría de las carreteras solo deben ser accesibles por un usuario autenticado. Por lo tanto, hemos configurado una página de autenticación para autenticar al usuario. Utilizamos la sesión HTTP para almacenar el perfil de usuario autenticado.
Para permitir que un usuario en las carreteras protegidas, hemos configurado un filtro HTTP de autorización, que verifica si la sesión HTTP actual contiene un perfil de usuario autenticado. Si es así, el filtro permite al usuario, de lo contrario lo redirige a la página de conexión.
Comenzamos la implementación del proyecto creando las clases ejecutivas (entidades de nuestro paquete de proyecto) como las habíamos definido durante el modelado. Luego creamos las clases y las interfaces, lo que nos permite acceder a la base de datos (paquetes de restaurantes). Finalmente, hemos implementado la posibilidad de identificarnos con nuestra aplicación todos juntos para acordar ciertos acuerdos para mantener nuestro proyecto coherente. Una vez que se han completado estos pasos, dividimos el trabajo, al dar a todos un cierto número de historias de usuarios, el trabajo se realizó hasta que se llevan a cabo todas las historias de los usuarios.
La mayoría de las historias de usuarios se hicieron fácilmente, excepto la historia del usuario: prepare una coincidencia. Durante nuestro modelado inicial de aplicaciones, habíamos representado mal los "muchos a muchos" enlaces que conectan a los jugadores con los partidos, no nos fascina una clase que representa a los equipos (clases de participación en nuestro proyecto). Entonces, cuando intentamos agregar jugadores a los juegos durante la fase de preparación, se lanzó una excepción y la preparación del partido no se realizó. Después de haber buscado con más detalle el funcionamiento de las "muchas a muchas" relaciones, nos dimos cuenta de que era imposible hacer dos relaciones de este tipo entre las mismas dos clases (aquí dos relaciones que conectan a los jugadores con los juegos, porque siempre hay dos equipos) sin pasar por una clase intermedia (aquí participación) para poder asociar adecuadamente a los jugadores con los partidos. Por lo tanto, tuvimos que modificar nuestro diagrama de clases para poder modelar adecuadamente nuestra nueva implementación, así como modificar las clases ejecutivas de los partidos y los jugadores y agregar la clase de participación para que nuestra aplicación funcione perfectamente.
La segunda dificultad encontrada no se refería a una historia del usuario en particular, sino un problema de codificación de datos. Después de terminar todas nuestras historias de usuarios, durante nuestras diversas pruebas y durante nuestras mejoras notamos que los acentos, normalmente compatibles con el UTF8, no se almacenaban correctamente en la base de datos. De hecho, todos los caracteres de acento en la base fueron reemplazados en otro formato. Después de mirar Internet, entendimos que el problema provenía de Wildfly y, para resolverlo, por lo tanto, simplemente tuvimos que cambiar la codificación del contenedor de servlet en la configuración de la comunidad silvestre. Para hacer esto, solo tuvimos que ir a la configuración de la Fly Wild y modificar la configuración de codificación predeterminada del contenedor de servlet por UTF-8.
También hemos encontrado problemas con la gestión del formato de fechas. Utilizamos el tipo de Date Local (API de fecha más reciente en Java) en nuestra clase ejecutiva, para almacenar la fecha programada de una coincidencia, por ejemplo. Ahora JSTL no tiene una función para formatear este tipo de fechas, porque todavía usa la antigua API de fecha Java. Por lo tanto, tuvimos que realizar un formato de mano en las páginas JSP que se muestran fechas (puede ir a ver este formato en la página consultMatches.jsp por ejemplo).
Una vez que se han superado estas dificultades, pudimos centrarnos en mejorar nuestra aplicación y ajustar errores menores.
Durante este proyecto, nos presentaron al desarrollo de aplicaciones comerciales con Yakarta EE. Aunque algunos de ellos ya tenían experiencia en el servidor en el lado del servidor, este proyecto fue para la ocasión de apropiarse de los estándares de desarrollo de la plataforma
Hemos podido establecer habilidades en la tecnología ORM JPA que ofrece una API muy rica que es poderosa. Ciertos mecanismos como las "muchas a muchos" relaciones nos han dado dificultades, pero tenemos que superarlos.
Finalmente, el aspecto colaborativo de este proyecto es una de sus fortalezas. De hecho, la motivación mutua es un motor poderoso que le permite superar cualquier tipo de dificultad. Esto también nos ha dado la oportunidad de aplicar habilidades ágiles de gestión de proyectos adquiridas en otros módulos, para colaborar de la manera más eficiente posible.


