dalle flow
1.0.0


¿Un humano en el bucle ? flujo de trabajo para crear imágenes HD a partir de texto
Dall · E Flow es un flujo de trabajo interactivo para generar imágenes de alta definición a partir de la solicitud de texto. Primero, aprovecha Dall · E-Mega, Glid-3 XL y la difusión estable para generar candidatos de imagen, y luego llama a Clip como servicio para clasificar los candidatos que escriben el aviso. El candidato preferido se alimenta a Glid-3 XL para la difusión, lo que a menudo enriquece la textura y los antecedentes. Finalmente, el candidato está mejorado a 1024x1024 a través de Swinir.
El flujo de Dall · E está construido con Jina en una arquitectura de cliente cliente, lo que le brinda alta escalabilidad, transmisión sin bloqueo y una interfaz pitónica moderna. El cliente puede interactuar con el servidor a través de GRPC/WebSocket/HTTP con TLS.
¿Por qué humano en el bucle? El arte generativo es un proceso creativo. Si bien los recientes avances de Dall · e desatan la creatividad de las personas, tener una UX/UI de salida única de un solo pronuncio bloquea la imaginación a una sola posibilidad, lo cual es malo sin importar cuán bueno sea este resultado único. El flujo de Dall · E es una alternativa a la línea única, al formalizar el arte generativo como un procedimiento iterativo.
Dall · E Flow está en la arquitectura de cliente cliente.
grpcs://api.clip.jina.ai:2096 (requiere jina >= v3.11.0 ), primero necesita obtener un token de acceso desde aquí. Consulte Use el clip como servicio para obtener más detalles.flow_parser.py .grpcs://dalle-flow.dev.jina.ai . Todas las conexiones ahora están con el cifrado TLS, reabren el cuaderno en Google Colab.p2.x8large .ViT-L/14@336px de clip como servicio, steps 100->200 .















































Usar cliente es súper fácil. Los siguientes pasos se ejecutan mejor en Jupyter Notebook o Google Colab.
Deberá instalar Dargarray y Jina primero:
pip install " docarray[common]>=0.13.5 " jinaHemos proporcionado un servidor de demostración para que juegue:
️ Debido a las solicitudes masivas, nuestro servidor puede ser retraso en la respuesta. Sin embargo, tenemos mucha confianza en mantener el tiempo de actividad alto. También puede implementar su propio servidor siguiendo la instrucción aquí.
server_url = 'grpcs://dalle-flow.dev.jina.ai'Ahora definamos el aviso:
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'Enviémoslo al servidor y visualicemos los resultados:
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Aquí generamos 24 candidatos, 8 de Dalle-Mega, 8 de Glid3 XL y 8 a partir de difusión estable, esto es como se define en num_images , que toma aproximadamente ~ 2 minutos. Puede usar un valor más pequeño si es demasiado largo para usted.

Los 24 candidatos están ordenados por clip como servicio, con índice 0 como el mejor candidato juzgado por el clip. Por supuesto, puede pensar de manera diferente. ¿Observe el número en la esquina superior izquierda? Seleccione el que más le guste y obtenga una mejor vista:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
Ahora enviemos los candidatos seleccionados al servidor para su difusión.
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Esto dará 36 imágenes basadas en la imagen seleccionada. Puede permitir que el modelo improvise más dando skip_rate un valor cercano a cero, o un valor cercano a uno para forzar su cercanía a la imagen dada. Todo el procedimiento toma aproximadamente ~ 2 minutos.

Seleccione la imagen que más le guste y dale un vistazo más de cerca:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
Finalmente, envíe al servidor para el último paso: mejora a 1024 x 1024px.
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()¡Eso es todo! Es el indicado . Si no está satisfecho, repita el procedimiento.

Por cierto, Darterray es una estructura de datos poderosa y fácil de usar para datos no estructurados. Es súper productivo para los científicos de datos que trabajan en dominio multimodal. Para obtener más información sobre Dargarray, consulte los documentos.
Puede alojar su propio servidor siguiendo la instrucción a continuación.
Dall · E Flow necesita una GPU con 21GB VRAM en su pico. Todos los servicios se encuentran en esta GPU, esto incluye (aproximadamente)
config.yml , 512x512)Los siguientes trucos razonables se pueden usar para reducir aún más VRAM:
Requiere al menos 50 GB de espacio libre en el disco duro, principalmente para descargar modelos previos a la petróleo.
Se requiere Internet de alta velocidad. Internet lento/inestable puede lanzar un tiempo de espera frustrante al descargar modelos.
El entorno solo de CPU no se prueba y probablemente no funcionará. Google Colab es probable que oom, por lo tanto, también no funcionará.

Si ha instalado Jina, el diagrama de flujo anterior se puede generar a través de:
# pip install jina
jina export flowchart flow.yml flow.svgSi desea utilizar la difusión estable, primero deberá registrar una cuenta en el sitio web Huggingface y aceptar los términos y condiciones para el modelo. Después de iniciar sesión, puede encontrar la versión del modelo requerida yendo aquí:
CompVis / SD-V1-5-Inpainting.CKPT
En la sección Descargar la sección de pesas , haga clic en el enlace para sd-v1-x.ckpt . Los últimos pesos al momento de escribir son sd-v1-5.ckpt .
Usuarios de Docker : coloque este archivo en una carpeta llamada ldm/stable-diffusion-v1 y cambie el nombre de IT model.ckpt . Siga las instrucciones a continuación cuidadosamente porque SD no está habilitado de forma predeterminada.
Usuarios nativos : coloque este archivo en dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt después de terminar el resto de los pasos en "Ejecutar de forma nativa". Siga las instrucciones a continuación cuidadosamente porque SD no está habilitado de forma predeterminada.
Hemos proporcionado una imagen de Docker preconstruida que se puede extraer directamente.
docker pull jinaai/dalle-flow:latestHemos proporcionado un DockerFile que le permite ejecutar un servidor fuera de la caja.
Nuestro Dockerfile está usando CUDA 11.6 Como la imagen base, es posible que desee ajustarla de acuerdo con su sistema.
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .El edificio tomará 10 minutos con velocidad promedio de Internet, lo que resulta en una imagen de Docker de 18 GB.
Para ejecutarlo, simplemente haz:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowAlternativamente, también puede ejecutar algunos flujos de trabajo habilitados o deshabilitados para evitar bloqueos fuera de memoria. Para hacer eso, pase una de estas variables de entorno:
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
Por ejemplo, si desea deshabilitar los flujos de trabajo GLID3XL, ejecute:
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cache evita la descarga repetida del modelo en cada ejecución de Docker.-p 51005:51005 es su puerto público anfitrión. Asegúrese de que las personas puedan acceder a este puerto si está sirviendo públicamente. El segundo par es el puerto definido en flujo.yml.ENABLE_STABLE_DIFFUSION .ENABLE_CLIPSEG .ENABLE_REALESRGAN . La difusión estable solo se puede habilitar si ha descargado los pesos y los hace disponibles como un volumen virtual mientras habilita el indicador ambiental ( ENABLE_STABLE_DIFFUSION ) para SD .
Debería haber colocado previamente los pesos en una carpeta llamada ldm/stable-diffusion-v1 y los ha etiquetado con model.ckpt . Reemplace YOUR_MODEL_PATH/ldm a continuación con la ruta en su propio sistema para encender los pesos en la imagen Docker.
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowDebería ver la pantalla como seguir una vez ejecutándose:
Tenga en cuenta que, a diferencia de ejecutar de forma nativa, ejecutar dentro de Docker puede dar una barra de progreso menos vívida, registros de color e impresiones. Esto se debe a las limitaciones del terminal en un contenedor Docker. No afecta el uso real.
Ejecutar de forma nativa requiere algunos pasos manuales, pero a menudo es más fácil depurar.
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.gitDebe tener la siguiente estructura de carpeta:
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -Hay un par de modelos que necesitamos descargar para Glid-3-XL si está utilizando eso:
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - Tanto clipseg como RealESRGAN requieren que establezca una ruta de carpeta de caché correcta, generalmente algo así como $ Home/.
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24 Ahora estás bajo dalle-flow/ , ejecute el siguiente comando:
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.ymlDeberías ver esta pantalla inmediatamente:

Al principio, tomará ~ 8 minutos descargar el modelo Dall · E Mega y otros modelos necesarios. Las ejecuciones de procedimiento solo deben tardar ~ 1 minuto en llegar al mensaje de éxito.
Cuando todo esté listo, verás:
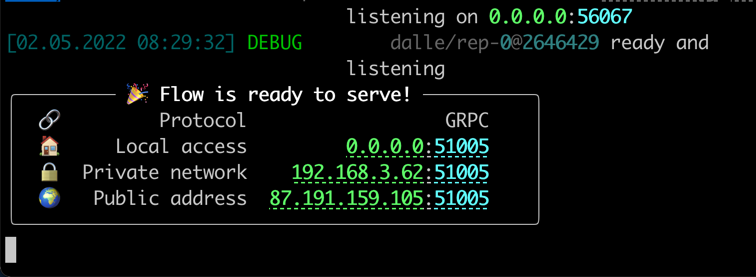
¡Felicitaciones! Ahora debería poder ejecutar el cliente.
Puede modificar y extender el flujo del servidor como desee, por ejemplo, cambiar el modelo, agregar persistencia o incluso publicar automáticamente a Instagram/OpenSea. Con Jina y Dargarray, puede hacer fácilmente la nube de flujo de flujo y listo para la producción.
Para reducir el uso de VRAM, puede usar el CLIP-as-service como ejecutor externo disponible gratuitamente en grpcs://api.clip.jina.ai:2096 .
Primero, asegúrese de haber creado un token de acceso desde el sitio web de la consola, o CLI como lo siguiente
jina auth token create < name of PAT > -e < expiration days > Luego, debe cambiar las configuraciones relacionadas con el ejecutor ( host , port , external , tls y grpc_metadata ) desde flow.yml .
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion] También puede usar flow_parser.py para generar automáticamente y ejecutar el flujo utilizando el CLIP-as-service como ejecutor externo:
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
️ grpc_metadatasolo está disponible después de Jinav3.11.0. Si está utilizando una versión anterior, actualice a la última versión.
Ahora, puede usar el CLIP-as-service gratuito en su flujo.
El flujo de Dall · e está respaldado por Jina Ai y con licencia bajo Apache-2.0. Estamos contratando activamente ingenieros de IA, ingenieros de soluciones para construir el próximo ecosistema de búsqueda neural en código abierto.


