detail_tts
1.0.0
The model newly proposed three significant important methods to become the best practice of AR TTS.
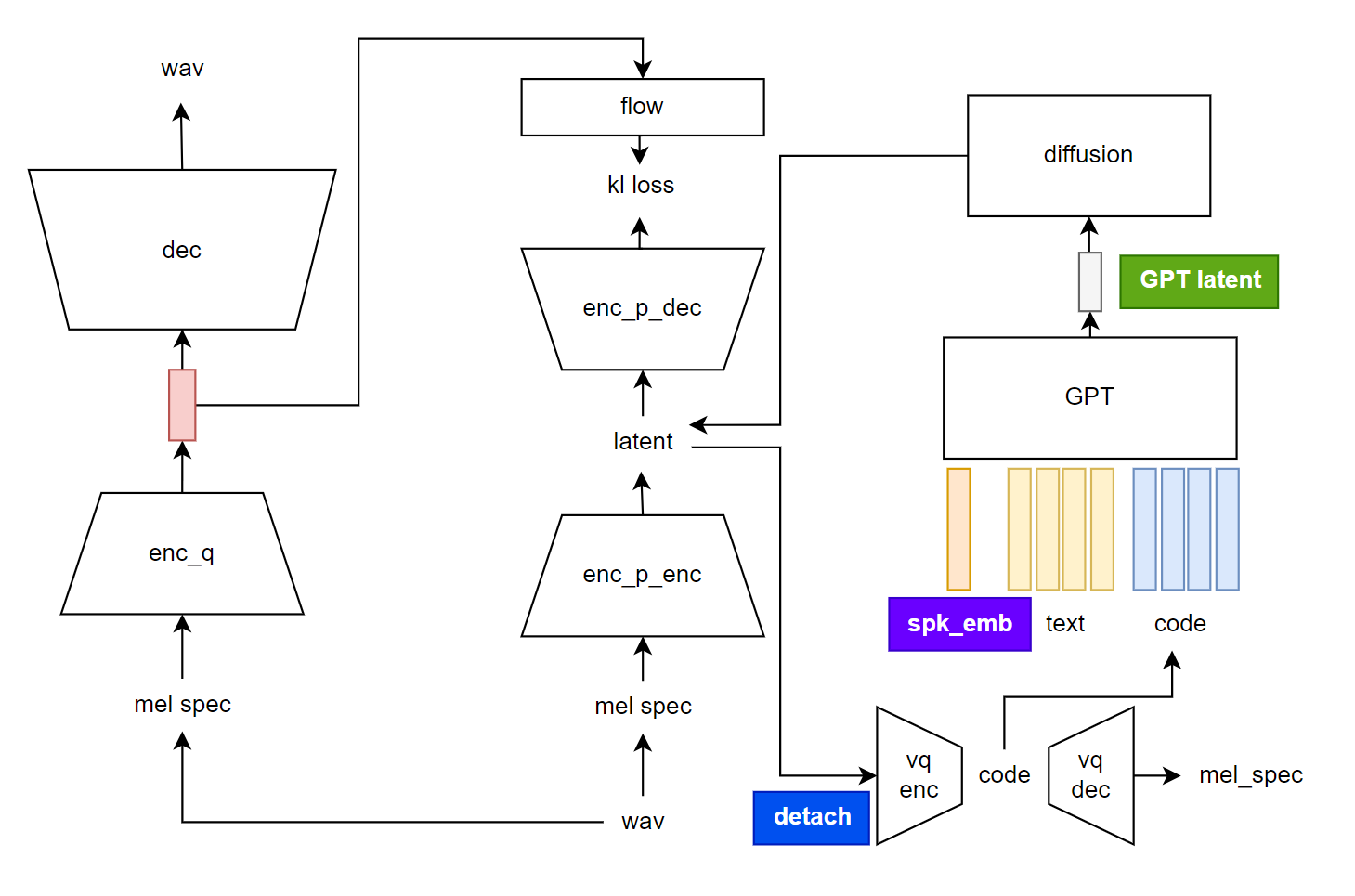
Here is the result obtained after the model was trained on 10000 hours of very dirty data. The model can be easily scaled up with many low quality data.
prompt 0
generated 0
prompt 1
generated 1
prompt 2
generated 2
check api.py
Change the path contains audios in script and run
python prepare/0_vad_asr_save_to_jsonl.py
accelerate launch train.py
For fine tuning, change the pretrain model load path.
VQ and VITS from GSV
Diffusion and GPT from tortoise


