attviz
1.0.0
 Attviz - Selbstversorgung einfach gemacht
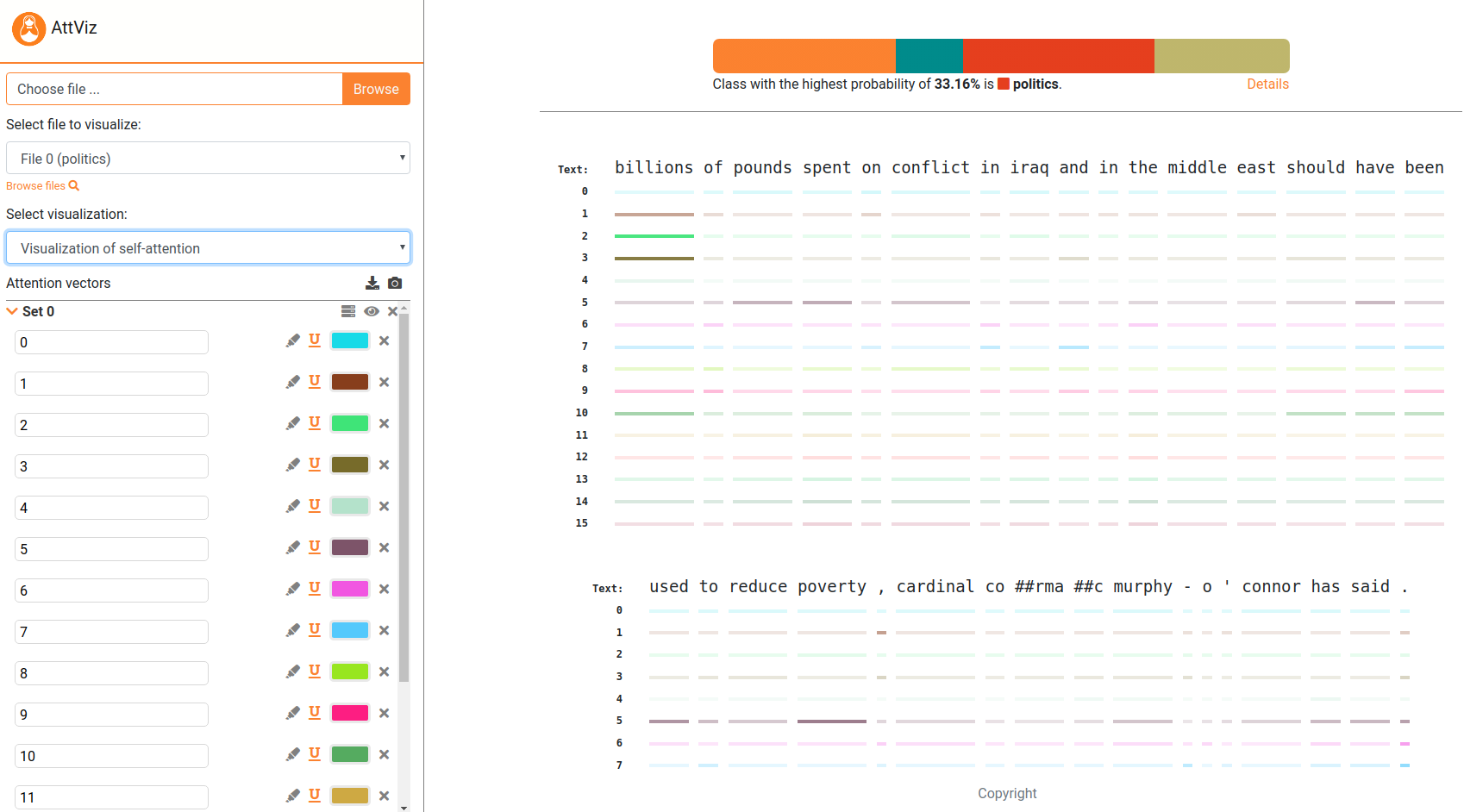
Attviz - Selbstversorgung einfach gemachtNeuronale Sprachmodelle sind die hochmodernen für die meisten sprachbezogenen Aufgaben. Eine der Möglichkeiten, ihr Verhalten zu untersuchen, ist jedoch die Visualisierung . Wir präsentieren Attviz, einen einfachen Webserver, der für die Erkundung der Aufmerksamkeit auf Instanzebene geeignet ist, online. Der Server ist live bei Attviz.
Aktueller Vordruck:
@inproceedings{skrlj-etal-2021-exploring,
title = "Exploring Neural Language Models via Analysis of Local and Global Self-Attention Spaces",
author = "{v{S}}krlj, Bla{v{z}} and
Sheehan, Shane and
Er{v{z}}en, Nika and
Robnik-{v{S}}ikonja, Marko and
Luz, Saturnino and
Pollak, Senja",
booktitle = "Proceedings of the EACL Hackashop on News Media Content Analysis and Automated Report Generation",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.hackashop-1.11",
pages = "76--83",
abstract = "Large pretrained language models using the transformer neural network architecture are becoming a dominant methodology for many natural language processing tasks, such as question answering, text classification, word sense disambiguation, text completion and machine translation. Commonly comprising hundreds of millions of parameters, these models offer state-of-the-art performance, but at the expense of interpretability. The attention mechanism is the main component of transformer networks. We present AttViz, a method for exploration of self-attention in transformer networks, which can help in explanation and debugging of the trained models by showing associations between text tokens in an input sequence. We show that existing deep learning pipelines can be explored with AttViz, which offers novel visualizations of the attention heads and their aggregations. We implemented the proposed methods in an online toolkit and an offline library. Using examples from news analysis, we demonstrate how AttViz can be used to inspect and potentially better understand what a model has learned.",
}
Um das folgende Beispiel zu befolgen, installieren Sie bitte die Anforderungen aus den Anforderungen.txt, indem Sie EG machen.
pip install -r requirements.txt
Attviz ist vollständig kompatibel mit Pytorch_Transformers Library!
Attviz akzeptiert den Aufmerksamkeitsraum, der in Form von JSON -Objekten codiert ist und die mithilfe der bereitgestellten Skripte konstruiert werden kann. Ein End-to-End-Beispiel, das zuerst ein Bert-basierter Modell zu einer Multiclas-Klassifizierungsaufgabe trainiert und als nächstes es verwendet, um Aufmerksamkeitsdaten zu erhalten, wird als nächstes angegeben.
## first build a model, then generate server input.
from generate_server_input import *
from build_bert_classifier import *
## STEP 1: A vanilla BERT-base model.
train_seq , dev_seq , train_tar , dev_tar = read_dataset ( "data" , "hatespeech" ) ## hatespeech or bbc are in the repo!
bert_model = get_bert_base ( train_seq , dev_seq , train_tar , dev_tar , weights_dir = "transformer_weights" , cuda = False ) ## for cuda, you might need the apex library
## STEP 2: Predict, attend to and generate final json.
weights = "transformer_weights" ## Any HuggingFace model dump can be used!
test_data = "data/hatespeech/test.tsv"
delimiter = " t "
text_field = "text_a"
label_field = "label"
number_of_attention_heads = 12
label_names = [ "no" , "some" , "very" , "disturbing" ] #['business','entertainment','politics','sport']
segment_delimiter = "|||"
## Obtain the attention information and create the output object.
## Subsample = True takes each 10th sample, useful for prototyping.
model = BertForSequenceClassification . from_pretrained ( weights ,
num_labels = len ( label_names ),
output_hidden_states = True ,
output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( "bert-base-uncased" )
out_obj = get_json_from_weights ( model ,
tokenizer ,
test_data = test_data ,
delimiter = delimiter ,
text_field = text_field ,
label_field = label_field ,
number_of_attention_heads = number_of_attention_heads ,
label_names = label_names ,
segment_delimiter = segment_delimiter ,
subsample = True )
## Output the extracted information to AttViz-suitable json.
with open ( 'generated_json_inputs/example_hatespeech_explanations.json' , 'w' ) as fp :
json . dump ( out_obj , fp )
## That's it! Simply upload this json to the attvis.ijs.si and explore!Der Server enthält außerdem einige vorbelastete Beispiele (generated_json_inputs), prüfen Sie diese auch (laden Sie auf Server hoch und erforschen).
Wenn man aufgrund von Datenschutzbedenken in lokaler Ausrichtung von Attviz die Anweisungen als nächstes befolgen möchte. Installieren Sie Node.js. Dann,
npm install express
Als nächstes ist es so einfach wie:
node embViz.js
Gehen Sie zum Browser und geben Sie "Localhost: 3310" ein. Ändern Sie die Ports nach Belieben.
Das Tool wird aktiv entwickelt, Änderungen werden zumindest in gewissem Maße erwartet. Mit eigenem Risiko verwenden.
Bitte öffnen Sie eine Pull -Anfrage, ein Problem oder schreiben Sie uns, wenn Sie einige interessante Anwendungsfälle dieser Methodik haben!
Der Code wurde mit gleichen Beiträgen von Nika Eržen und Blaž Škrlj entwickelt


