liif
1.0.0
Dieses Repository enthält die offizielle Implementierung für Liif, die im folgenden Artikel eingeführt wurden:
Lernen kontinuierlicher Bilddarstellung mit der lokalen impliziten Bildfunktion
Yinbo Chen, Sifei Liu, Xiaolong Wang
CVPR 2021 (mündlich)
Die Projektseite mit Video ist unter https://yinboc.github.io/liif/.
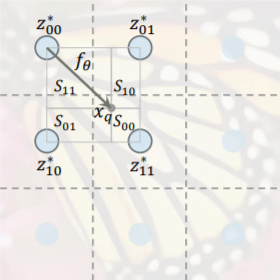
Wenn Sie unsere Arbeit in Ihrer Forschung nützlich finden, zitieren Sie bitte:
@inproceedings{chen2021learning,
title={Learning continuous image representation with local implicit image function},
author={Chen, Yinbo and Liu, Sifei and Wang, Xiaolong},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8628--8638},
year={2021}
}
| Modell | Dateigröße | Herunterladen |
|---|---|---|
| EDSR-Baseline-Liif | 18m | Dropbox | Google Drive |
| Rdn-liif | 256 m | Dropbox | Google Drive |
[MODEL_PATH] bezeichnet die .pth -Datei) python demo.py --input xxx.png --model [MODEL_PATH] --resolution [HEIGHT],[WIDTH] --output output.png --gpu 0
mkdir load zum Einstellen der Datensatzordner.
Div2k : mkdir und cd in load/div2k . Download HR -Bilder und BICUBIC -Validierungs -LR -Bilder von der Div2k -Website (dh Train_hr, valid_hr, valid_lr_x2, valid_lr_x3, valid_lr_x4). unzip diese Dateien, um die Bildordner zu erhalten.
Benchmark -Datensätze : cd in load/ . Download und tar -xf Die Benchmark -Datensätze (bereitgestellt von diesem Repo), erhalten Sie einen load/benchmark -Ordner mit Unterordnern Set5/, Set14/, B100/, Urban100/ .
Celebahq : mkdir load/celebAHQ und cp scripts/resize.py load/celebAHQ/ cd load/celebAHQ/ . Download und unzip data1024x1024.zip über den Google Drive -Link (bereitgestellt von diesem Repo). Führen Sie python resize.py aus 256/, 128/, 64/, 32/ Laden Sie den Split.json herunter.
0. Vorrunde
Verwenden Sie für train_liif.py oder test.py --gpu [GPU] , um den GPUs (z. B. --gpu 0 oder --gpu 0,1 ) anzugeben.
Für train_liif.py ist der Speicherordner standardmäßig bei save/_[CONFIG_NAME] . Wir können verwenden --name , um bei Bedarf einen Namen anzugeben.
Für Datensatz-Argumente in Konfigurationen bedeutet cache: in_memory das Vorlading in den Speicher (kann einen großen Speicher erfordern, z. B. ~ 40 GB für Div2k), cache: bin bezeichnet das Erstellen von Binärdateien (in einem Geschwisterordner) zum ersten Mal, cache: none bezeichnet direkte Belastung. Wir können es gemäß den Hardware -Ressourcen ändern, bevor wir die Trainingsskripte ausführen.
1. Div2k -Experimente
Zug : python train_liif.py --config configs/train-div2k/train_edsr-baseline-liif.yaml (mit dem Backbone mit dem EDSR-Baseline, für RDN edsr-baseline durch rdn ). Wir verwenden 1 GPU für das Training EDSR-Baseline-LIIF und 4 GPU für RDN-LIIF.
Test : bash scripts/test-div2k.sh [MODEL_PATH] [GPU] für div2k Validierungssatz, bash scripts/test-benchmark.sh [MODEL_PATH] [GPU] für Benchmark-Datensätze. [MODEL_PATH] ist der Pfad zu einer .pth Datei, wir verwenden epoch-last.pth im entsprechenden Speicherordner.
2. Celebahq Experimente
Zug : python train_liif.py --config configs/train-celebAHQ/[CONFIG_NAME].yaml .
Test : python test.py --config configs/test/test-celebAHQ-32-256.yaml --model [MODEL_PATH] (oder test-celebAHQ-64-128.yaml für eine andere Aufgabe). Wir verwenden epoch-best.pth im entsprechenden Speicherordner.


