toyOS
可运行版本
Ein Spielzeugbetrieb, 32bit impliziert schließlich eine einfache interaktive Hülle 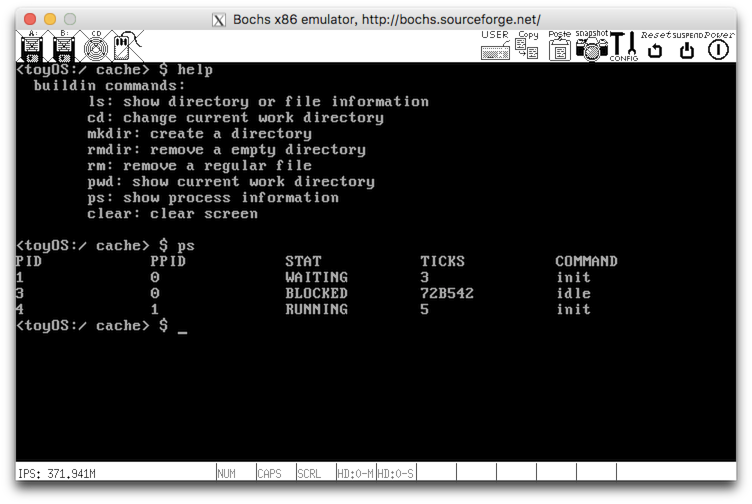
To-Do-Liste:
Insgesamt gibt es zwei Festplatten, das System selbst ist auf der Hauptscheibe installiert, und der Kofferraummodus von MBR wird angewendet, und der Prozess des MBR-> Boot-Laders-Kernnels wird verwendet.
MBR befindet sich in 1 Sektor, beginnend LBA 0号扇区
Boot Loader befindet sich in 4 Sektoren, beginnend mit LBA 2号扇区der Festplatte
Kernel befindet sich in 200 Sektoren, beginnend mit dem Disk LBA 9号扇区
Das Dateisystem ist auf der Sklavenscheibe implementiert. Dies ist möglicherweise nicht sehr vernünftig. Wenn das Dateisystem auf der Logik des kommerziellen Systems basiert, sollte es jetzt implementiert werden und dann ist das Betriebssystem in der entsprechenden Partition installiert.
Speicherpaging, eine Seite ist 4KB
Die Speicherverwaltung übernimmt die Bitmap -Verwaltung und unterscheidet sich durch die Größe von Speicher. Wenn es größer als 1024 Bytes ist, wird es direkt nach Seite zugeordnet.
Wenn es weniger als 1024 Bytes auf der Grundlage der Zuweisung von Arena per Seite sind, verwenden Sie die Leerlaufblockchain in Arena zur Zuweisung und Kontrolle.
Obwohl der Paging -Mechanismus aktiviert ist, wird die Schaltfunktion von Speicherseiten und Festplatten nicht implementiert.
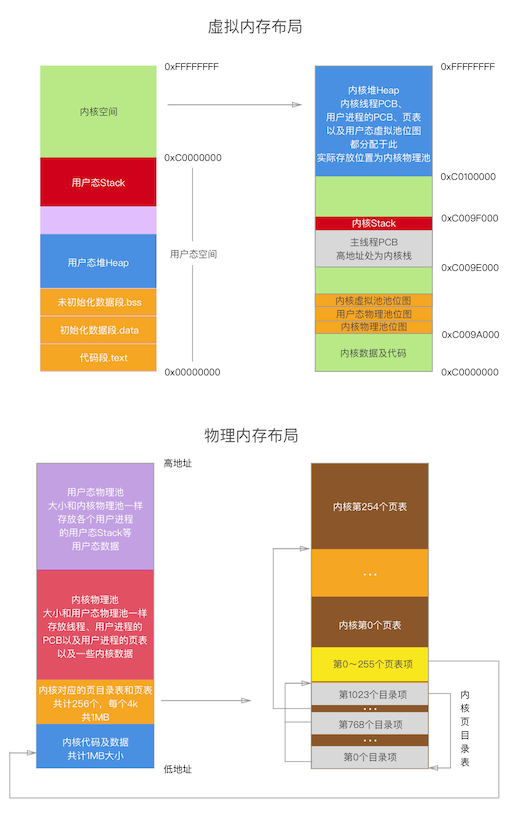
PCB ist 1 Seitengröße
Die Kernessenz der Thread -Planung besteht darin, die PCB zu wechseln, indem die ESP -Zeigerschaltung per Clock -Interrupt gesteuert wird. Die Priorität spiegelt sich in der Länge der Laufzeitscheibe jedes Fadens wider.
Die Implementierung des Prozesses basiert auf Threads, und die Auswahl von TSS basiert auf Linux, wobei einzelne TSS zur Sicherung der Stapel von Stapeln und Stapelzeigern der Stapel 0 verwendet wird. Der größte Unterschied zu einem Thread besteht darin, dass der Prozess eine Seitenadresse im PCB hat, was der größte Unterschied zwischen einem Prozess und einem Thread ist. Der Prozess hat wirklich einen eigenen unabhängigen virtuellen Speicherplatz.
Es gibt keinen effizienten Algorithmus bei der Planung. Verwenden Sie einfach die Warteschlaufe -Schleifenplanung
Implementierung des Leerlaufs
Die Implementierung des Leerlaufs ist sehr einfach. Wenn Sie den Zeitplan zum ersten Mal erhalten, blockieren Sie ihn und geben ihn aus der CPU heraus. Wenn der Scheduler den Versand erneut ausführt, wird der Leerlauf -Thread erweckt, wenn kein Fertig -Thread oder Prozess in der Ready -Warteschlange gefunden wird. Zu diesem Zeitpunkt setzt der Leerlauf -Faden die CPU durch hlt aus. Wenn die Zeitscheibe aufgebraucht wird und die CPU keinen Bereitschaftsprozess oder Faden gefunden hat, ersetzen Sie den Leerlaufgewinde weiter durch die CPU. Zu diesem Zeitpunkt blockiert sich der Leerlauf weiterhin und wiederholt dann den oben genannten Planungsprozess.
// 空载任务
static void idle ( void * arg ) {
while ( 1 ) {
thread_block ( TASK_BLOCKED );
asm volatile ( "sti; hlt" : : : "memory" );
}
}Prozessgabel
Die Gabel des Prozesses kopiert zuerst die PCB des aktuellen Prozesses und erstellen Sie dann eine neue Seitentabelle über die virtuelle Poolbitmap des aktuellen Prozesses. Die Korrespondenz der virtuellen Adresse ist genau der gleiche wie im ursprünglichen Prozess. Schließlich wird eine Interrupt -Site gefälscht und der Kinderprozess in die Planungswarteschlange hinzugefügt und wartet, bis die Planung ausgeführt wird. In der gefälschten Interrupt -Site wird der EAX in der PCB des untergeordneten Prozesss auf 0 geändert, was bedeutet, dass der Rückgabewert der Gabel im neuen Prozess 0 beträgt, während die EAX im PCB des übergeordneten Prozesses unverändert bleibt und die PID des untergeordneten Prozesss darstellt. Der übergeordnete Prozess kehrt bis zum Ende des Systemaufrufs zurück, während der untergeordnete Prozess direkt durch die Interrupt -Exit -Funktion zurückkehrt.
Process Exec
Die Implementierung von Exec lädt zunächst die ELF -Datei von der Festplatte in den Speicher, ändert dann den Prozessnamen im PCB des aktuellen Prozesses und setzt die vom Prozess erforderlichen Parameter in das vereinbarte Register ein und ändert EIP, indem er den Einstiegspunkt der ELF, Fälschung des Interrupt -Standorts, und führt den neuen Vorgang sofort durch, indem Sie die Interpretd -Exit -Funktion direkt aufrufen.
Unter ihnen wird der Einstiegspunkt von ELF durch die Implementierung einer extrem einfachen CRT selbst implementiert, die einen Starteintrag angibt und die vereinbarten Parameterregister in den 3-Level-Stack drückt und die Hauptfunktion des externen Befehls aufruft, um die Passierung des Parameters zu realisieren.
[bits 32]
extern main
extern exit
; 这是一个简易版的CRT
; 如果链接时候ld不指定-e main的话,那ld默认会使用_start来充当入口
; 这里的_start的简陋实现,充当了exec调用的进程从伪造的中断中返回时的入口地址
; 通过这个_start, 压入了在execv中存放用户进程参数的两个寄存器。然后call 用户进程main来实现了向用户进程传递参数
section .text
global _start
_start:
;下面这两个要和 execv 中 load 之后指定的寄存器一致
push ebx ;压入 argv
push ecx ;压入 argc
call main
; 压入main的返回值
push eax
call exit ; 不再返回,直接调度别的进程了,这个进程直接被回收了Prozess warten
Nach der Gabelung und Ausführung eines lokalen Befehls muss der übergeordnete Prozess im lokalen Wartewartungsprozess enden.
Die Implementierung hier besteht darin, den Aufruf von sys_wait -Systemen einzugeben, die gesamte Prozesswarteschlange zu durchqueren, den Prozess zu finden, dessen übergeordneter Prozess ein eigener suspendierter Zustand ist, dann den Rückgabwert in der PCB erhalten, die PCB- und Seitenverzeichnistabellen recyceln und aus der Planungswarteschlange entfernen. Wenn nach dem Durchqueren kein ausstehender Kinderprozess gefunden wird, blockieren Sie sich und warten Sie, bis der Kinderprozess aufwacht.
Prozessausgang
Während der Ausführung werden externe Befehle tatsächlich von einer einfachen CRT verpackt, die von sich selbst erstellt wurde. Der Hauptbefehl des einfachen CRT Call External erhält seinen Rückgabewert am Ende, übergeben Sie ihn zum Ausgang und rufen Sie anschließend auf
Die Implementierung hier macht hauptsächlich drei Dinge:
Der gesamte Prozess des Ladens externer Befehle und der Ausführung
Zunächst muss der externe Befehl eine int main(int argc, char **argv) bereitstellen. Beim Verknüpfen müssen Sie eine hausgemachte einfache CRT start.o mitbringen und schließlich die kompilierten externen Befehle in das Dateisystem schreiben.
Wenn ein externer Befehl ausgeführt werden soll, gibt der aktuelle Prozess einen Prozess, execv im neuen Prozess, der aktuelle Prozess wird warten, übergibt eine Adresse, um den Rückgabewert des untergeordneten Prozesses zu akzeptieren, und blockiert und wartet dann, bis der neue Prozess zurückgegeben wird. Der neue Prozess lädt externe Befehle aus dem Dateisystem in EMEVC in den Speicher und ändert den relevanten Inhalt in der PCB in die Informationen von externen Befehlen und verändert den EIP im PCB -Interrupt intr_exit an den _start -Eintrag des CRT (zum Zeitpunkt der neuen Vorstellung wurde der neue Prozess vollständig ersetzt. Der externe Befehl. Wenn die Hauptausführung der externen Befehl endet und zurückgibt, ruft CRT den Hauptrückgabewert auf, stecken Sie den Hauptrückgabewert in sys_exit in die entsprechende Position des PCB, recyceln Sie alle Ressourcen mit Ausnahme der PCB- und Seitenverzeichnis -Tabelle und blockieren Sie dann den übergeordneten Prozess und blockieren den untergeordneten Prozess. Nachdem der übergeordnete Prozess erweckt wurde, erhält das System Call sys_wait den Rückgabwert von der PCB der PCB des PCB des PCB des PCB des PCB des PCB des PCB des PCB des PCB des PCB des PCB, reinigt die PCB des PCB des untergeordneten Prozessprozesses. Zu diesem Zeitpunkt wurde der Kinderprozess ausgeführt und wird vollständig recycelt.
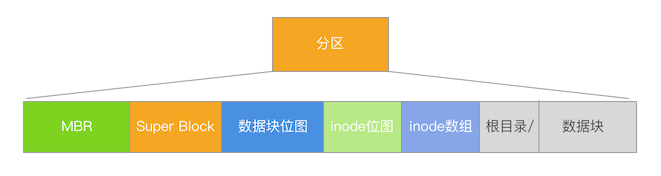
Die Implementierung des Dateisystems imitiert den Inode von Unix-ähnlichen Systemen
Die Partition begrenzt die Anzahl der Inodes 4096. Die CPU betreibt die Festplatte gemäß der Größe des Blocks (Cluster), und ein Block ist auf einen Sektor mit 512 Bytes eingestellt.
Inode unterstützt 12 direkte Blöcke und 1 indirekte Tabelle der ersten Ebene. Ein Block beträgt 512 Bytes in einem Sektor, sodass eine einzige Datei bis zu 140 * 512 Bytes unterstützt.
Inode -Struktur

Dateisystemlayout
Die Korrespondenz zwischen Dateideskriptor und Inode
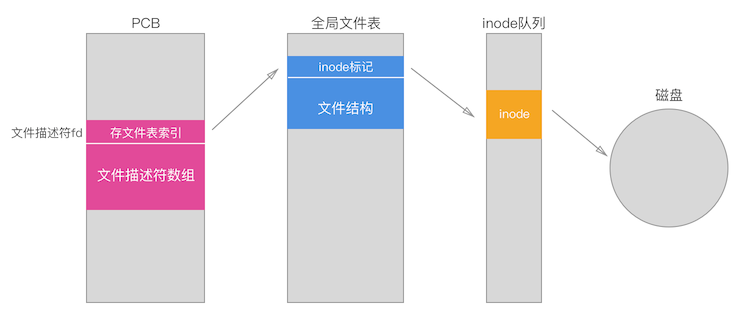
Die Implementierung der Pipeline hängt von der Dateistruktur im Dateisystem ab. Seine Essenz ist es, den Inode zu ersetzen, den die Dateistruktur ursprünglich mit einem Ringpufferraum im Kernelraum entsprechen sollte.
// 因为管道也是当作文件来对待,因此file结构体在针对真实文件和管道是有不同的意义
struct file {
// 文件操作的偏移指针, 当是管道是表示管道打开的次数
uint32_t fd_pos ;
// 文件的操作标志,当是管道是一个固定值0xFFFF
uint32_t fd_flag ;
// 对应的inode指针,当是管道时指向管道的环形缓冲区
struct inode * fd_inode ;
}; Da der Kernelraum geteilt wird, kann die Kommunikation zwischen verschiedenen Prozessen durch Lese- und Schreibpipelines erreicht werden. Das Lese- und Schreiben der Pipeline ist in sys_write und sys_read eingekapselt. Daher gibt es keinen Unterschied zwischen dem Betrieb der Pipeline und dem Betrieb normaler Dateien.
Das Wesen der Umleitung besteht darin, die Adresse der entsprechenden globalen Deskriptor -Tabelle in der PCB -Dateideskriptor -Tabelle zu ändern, und dann wird der Betrieb des entsprechenden Dateideskriptors auf die neue Datei verweist.
Die Implementierung des Pipeline -Charakters | In der Hülle wird durch Umleitungsstandardeingang und Standardausgabe in die Pipeline erreicht.
int32_t sys_read ( int32_t fd , void * buf , uint32_t count ) {
if ( fd == stdin_no ) {
if ( is_pipe ( fd )) {
// 从已经重定向好管道中读
ret = pipe_read ( fd , buf , count );
} else {
// 从键盘获取输入
}
} else if ( is_pipe ( fd )) {
// 读管道
ret = pipe_read ( fd , buf , count );
} else {
// 读取普通文件
}
return ret ;
}
int32_t sys_write ( int32_t fd , const void * buf , uint32_t count ) {
if ( fd == stdout_no ) {
if ( is_pipe ( fd )) {
// 向已经重定向好管道中写入
return pipe_write ( fd , buf , count );
} else {
// 向控制台输出内容
}
} else if ( is_pipe ( fd )) {
// 写管道
return pipe_write ( fd , buf , count );
} else {
// 向普通文件写入
}
}

