Stem Lem Pipeline
1.0.0
استخدم محول النص على أساس روسي (ولكن ليس فقط) العديد من الخلفية الناجمة والخلفية وميزات تحضير النص
pip install StemLemPipe
الغرض الرئيسي من StemLemPipe هو نصوص التحويل إلى مجموعات بيثون من السلاسل المفيدة التي يتم تقسيمها 1- ، 2 ، 3- ، ... ، n-grams من الكلمات المحتوية و/أو الجذعية من هذه النصوص المقسمة بواسطة:
إلقاء نظرة على مفهوم خط أنابيب StemLemPipe :
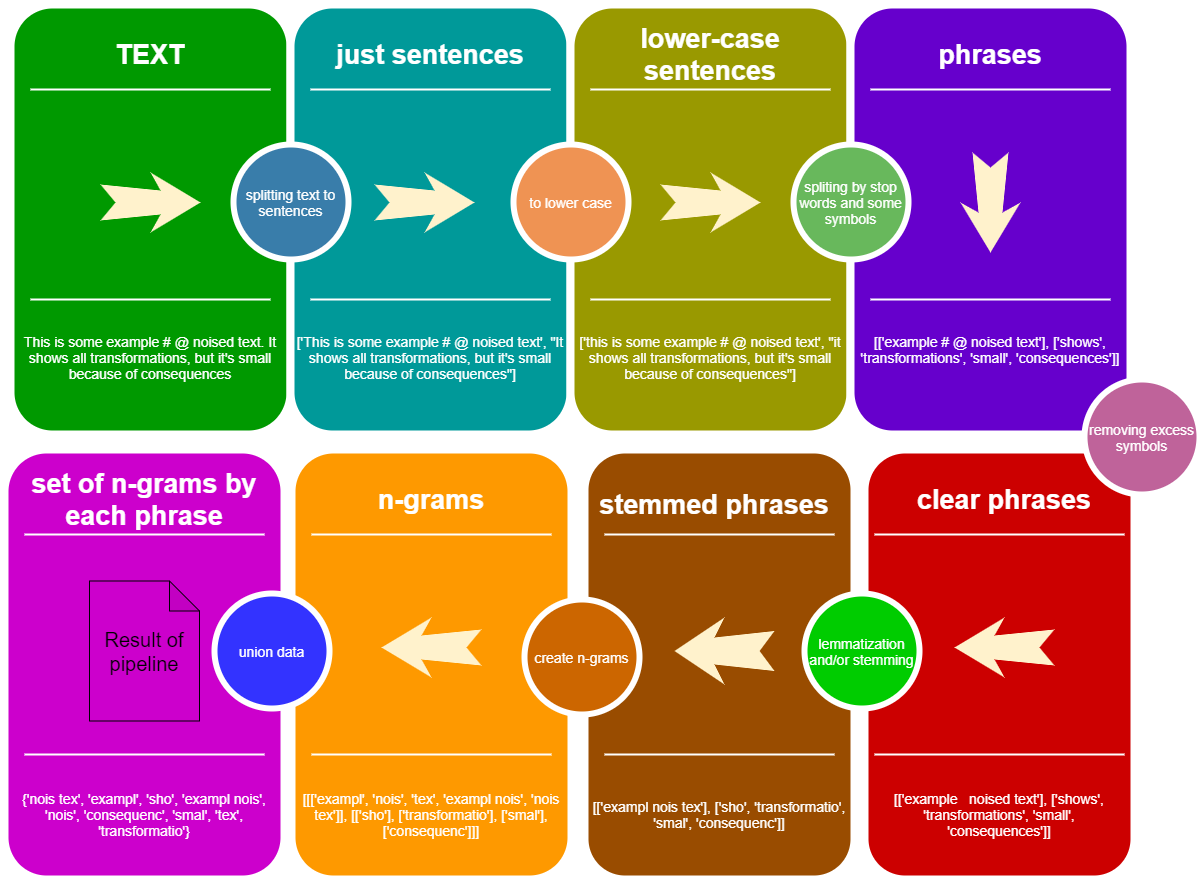
from StemLemPipe import phrases2lower , phrases_without_excess_symbols , phrases_transform , text2sentences , split_by_words , sentence_split , create_stemmer_lemmer , words_to_ngrams_list , sum_phrases , wordlist2set , stopwords , StemLemPipeline
text_example = """Lemmatization is the process of grouping together the different inflected forms of a word so they can be analysed as a single item. Lemmatization is similar to stemming but it brings context to the words. So it links words with similar meaning to one word."""
#text_example = "This is some example # @ noised text. It shows all transformations, but it's small because of consequences"
def print2 ( obj ):
print ( obj )
print ()
# create stemmer-lemmatizer pipeline function
stem_lem = create_stemmer_lemmer ( lemmatizer_backend = 'wordnet' , stemmer_backend = 'snowball' , language = 'en' )
# convert all text to list of sentences
sentences = text2sentences ( text_example )
print2 ( sentences )
# ['Lemmatization is the process of grouping together the different inflected forms of a word so they can be analysed as a single item', 'Lemmatization is similar to stemming but it brings context to the words', 'So it links words with similar meaning to one word']
# transform each phrase to lower case
clean_sentences = phrases2lower ( sentences )
print2 ( clean_sentences )
# ['lemmatization is the process of grouping together the different inflected forms of a word so they can be analysed as a single item', 'lemmatization is similar to stemming but it brings context to the words', 'so it links words with similar meaning to one word']
# split each sentence to list of phrases between separators and stop words
phrases = [ sentence_split ( sentence , separators = ',;' , stop_words = stopwords ( 'en' )) for sentence in clean_sentences ]
print2 ( phrases )
# [['lemmatization', 'process', 'grouping together', 'different inflected forms', 'word', 'can', 'analysed', 'single item'], ['lemmatization', 'similar', 'stemming', 'brings context', 'words'], ['links words', 'similar meaning', 'one word']]
# remove excess symbols from phrases
char_phrases = phrases_without_excess_symbols ( phrases , include_alpha = True , include_numbers = True )
print2 ( char_phrases )
# [['lemmatization', 'process', 'grouping together', 'different inflected forms', 'word', 'can', 'analysed', 'single item'], ['lemmatization', 'similar', 'stemming', 'brings context', 'words'], ['links words', 'similar meaning', 'one word']]
# stem and lemmatize all words in all phrases
stemmed_phrases = phrases_transform ( char_phrases , func = stem_lem )
print2 ( stemmed_phrases )
# [['lemmatizatio', 'proce', 'group togeth', 'differ inflect form', 'wor', 'ca', 'analys', 'singl ite'], ['lemmatizatio', 'simila', 'stemmin', 'bring contex', 'wor'], ['link word', 'similar meanin', 'one wor']]
# convert each phrase to list of n-grams
n_grams = phrases_transform ( stemmed_phrases , func = lambda w : words_to_ngrams_list ( w . split (), n_min = 1 , n_max = 2 ))
print2 ( n_grams )
# [[['lemmatizatio'], ['proce'], ['group', 'togeth', 'group togeth'], ['differ', 'inflect', 'form', 'differ inflect', 'inflect form'], ['wor'], ['ca'], ['analys'], ['singl', 'ite', 'singl ite']], [['lemmatizatio'], ['simila'], ['stemmin'], ['bring', 'contex', 'bring contex'], ['wor']], [['link', 'word', 'link word'], ['similar', 'meanin', 'similar meanin'], ['one', 'wor', 'one wor']]]
# convert list of list of list to just list
total = sum_phrases ( n_grams )
print2 ( total )
# ['lemmatizatio', 'proce', 'group', 'togeth', 'group togeth', 'differ', 'inflect', 'form', 'differ inflect', 'inflect form', 'wor', 'ca', 'analys', 'singl', 'ite', 'singl ite', 'lemmatizatio', 'simila', 'stemmin', 'bring', 'contex', 'bring contex', 'wor', 'link', 'word', 'link word', 'similar', 'meanin', 'similar meanin', 'one', 'wor', 'one wor']
# convert all objects to set
total_set = wordlist2set ( total , save_order = False )
print2 ( total_set )
# {'wor', 'ite singl', 'group', 'stemmin', 'meanin similar', 'form inflect', 'differ inflect', 'lemmatizatio', 'analys', 'one', 'ite', 'group togeth', 'ca', 'word', 'meanin', 'singl', 'inflect', 'similar', 'form', 'bring', 'contex', 'link', 'bring contex', 'link word', 'togeth', 'one wor', 'differ', 'proce', 'simila'}
# all these steps are equal to pipeline
pipe = StemLemPipeline ([
text2sentences , phrases2lower ,
lambda sentences : list ( map ( lambda s : sentence_split ( s , separators = ',;' , stop_words = stopwords ( 'en' )), sentences )),
lambda p : phrases_without_excess_symbols ( p , include_alpha = True , include_numbers = True ),
lambda p : phrases_transform ( p , stem_lem ),
lambda p : phrases_transform ( p , func = lambda w : words_to_ngrams_list ( w . split (), n_min = 1 , n_max = 2 )),
sum_phrases ,
lambda p : wordlist2set ( p , save_order = False )
])
pipe ( text_example )
# {'wor', 'ite singl', 'group', 'stemmin', 'meanin similar', 'form inflect', 'differ inflect', 'lemmatizatio', 'analys', 'one', 'ite', 'group togeth', 'ca', 'word', 'meanin', 'singl', 'inflect', 'similar', 'form', 'bring', 'contex', 'link', 'bring contex', 'link word', 'togeth', 'one wor', 'differ', 'proce', 'simila'}
print ( total_set == pipe ( text_example )) # true from StemLemPipe import phrases2lower , phrases_without_excess_symbols , phrases_transform , text2sentences , split_by_words , sentence_split , create_stemmer_lemmer , words_to_ngrams_list , sum_phrases , wordlist2set , stopwords , StemLemPipeline
text_example = """Если в жопе шило, я могу достать.
Я имею опыт, лучше "да" сказать.
Влагалище твое в тонус приведу.
Пиши адрес, я приду.
Мой член, словно банан, кривой
И в матку вплоть до дна зайдет,
И полчаса стоять смогет,
Как на границе часовой.
Ты будешь просто разрываться,
Когда начнем с тобой ебаться,
И в счастье будешь же казниться,
Что раньше не решилась соблазниться.
Я медленно сниму штаны с тебя,
И поцелуями сломлю твое сомненье,
От похоти войдешь ты в опьяненье,
Пока не кончишь от меня.
Я смазку принесу с собой,
Сначала ты почувствуешь прохладу,
Но буду жарить я своей большой трубой,
Пока не получу усладу.
Ты напиши, и я приду,
Если не буду очень занят,
Пощекочу твою пизду
Снутри и долго, ибо не устанет.
Я покусаю твою попу
И буду долго трахать в жопу,
Пока ментов не вызовут на вой
Той девки, что кайфует подо мной.
Потом сниму презерватив,
Мирамистином всё полью,
Минут пятнадцать перерыв —
И снова я на час в бою.
И шея будет вся в укусах и засосах,
И будет всё болеть, включая твою грудь,
Но через пару дней, тоскуя без вопросов,
Захочешь эту ночь вернуть."""
def print2 ( obj ):
print ( obj )
print ()
# create stemmer-lemmatizer pipeline function
stem_lem = create_stemmer_lemmer ( lemmatizer_backend = 'pymorphy' , stemmer_backend = 'snowball' )
# convert all text to list of sentences
sentences = text2sentences ( text_example )
print2 ( sentences )
# ['Если в жопе шило, я могу достать', 'Я имею опыт, лучше "да" сказать', 'Влагалище твое в тонус приведу', 'Пиши адрес, я приду', 'Мой член, словно банан, кривой И в матку вплоть до дна зайдет, И полчаса стоять смогет, Как на границе часовой', 'Ты будешь просто разрываться, Когда начнем с тобой ебаться, И в счастье будешь же казниться, Что раньше не решилась соблазниться', 'Я медленно сниму штаны с тебя, И поцелуями сломлю твое сомненье, От похоти войдешь ты в опьяненье, Пока не кончишь от меня', 'Я смазку принесу с собой, Сначала ты почувствуешь прохладу, Но буду жарить я своей большой трубой, Пока не получу усладу', 'Ты напиши, и я приду, Если не буду очень занят, Пощекочу твою пизду Снутри и долго, ибо не устанет', 'Я покусаю твою попу И буду долго трахать в жопу, Пока ментов не вызовут на вой Той девки, что кайфует подо мной', 'Потом сниму презерватив, Мирамистином всё полью, Минут пятнадцать перерыв — И снова я на час в бою', 'И шея будет вся в укусах и засосах, И будет всё болеть, включая твою грудь, Но через пару дней, тоскуя без вопросов, Захочешь эту ночь вернуть']
# transform each phrase to lower case
clean_sentences = phrases2lower ( sentences )
print2 ( clean_sentences )
# ['если в жопе шило, я могу достать', 'я имею опыт, лучше "да" сказать', 'влагалище твое в тонус приведу', 'пиши адрес, я приду', 'мой член, словно банан, кривой и в матку вплоть до дна зайдет, и полчаса стоять смогет, как на границе часовой', 'ты будешь просто разрываться, когда начнем с тобой ебаться, и в счастье будешь же казниться, что раньше не решилась соблазниться', 'я медленно сниму штаны с тебя, и поцелуями сломлю твое сомненье, от похоти войдешь ты в опьяненье, пока не кончишь от меня', 'я смазку принесу с собой, сначала ты почувствуешь прохладу, но буду жарить я своей большой трубой, пока не получу усладу', 'ты напиши, и я приду, если не буду очень занят, пощекочу твою пизду снутри и долго, ибо не устанет', 'я покусаю твою попу и буду долго трахать в жопу, пока ментов не вызовут на вой той девки, что кайфует подо мной', 'потом сниму презерватив, мирамистином всё полью, минут пятнадцать перерыв — и снова я на час в бою', 'и шея будет вся в укусах и засосах, и будет всё болеть, включая твою грудь, но через пару дней, тоскуя без вопросов, захочешь эту ночь вернуть']
# split each sentence to list of phrases between separators and stop words
phrases = [ sentence_split ( sentence , separators = ',;' , stop_words = stopwords ( 'ru' )) for sentence in clean_sentences ]
print2 ( phrases )
# [['жопе шило', 'могу достать'], ['имею опыт', '"да"'], ['влагалище твое', 'тонус приведу'], ['пиши адрес', 'приду'], ['член', 'словно банан', 'кривой', 'матку вплоть', 'дна зайдет', 'полчаса стоять смогет', 'границе часовой'], ['разрываться', 'начнем', 'ебаться', 'счастье', 'казниться', 'решилась соблазниться'], ['медленно сниму штаны', 'поцелуями сломлю твое сомненье', 'похоти войдешь', 'опьяненье', 'кончишь'], ['смазку принесу', 'почувствуешь прохладу', 'жарить', 'большой трубой', 'получу усладу'], ['напиши', 'приду', 'пощекочу твою пизду снутри', 'ибо', 'устанет'], ['покусаю твою попу', 'трахать', 'жопу', 'ментов', 'вызовут', 'вой той девки', 'кайфует подо'], ['сниму презерватив', 'мирамистином', 'полью', 'минут', 'перерыв —', 'час', 'бою'], ['шея', 'укусах', 'засосах', 'болеть', 'включая твою грудь', 'пару дней', 'тоскуя', 'вопросов', 'захочешь', 'ночь вернуть']]
# remove excess symbols from phrases
char_phrases = phrases_without_excess_symbols ( phrases , include_alpha = True , include_numbers = True )
print2 ( char_phrases )
# [['жопе шило', 'могу достать'], ['имею опыт', 'да'], ['влагалище твое', 'тонус приведу'], ['пиши адрес', 'приду'], ['член', 'словно банан', 'кривой', 'матку вплоть', 'дна зайдет', 'полчаса стоять смогет', 'границе часовой'], ['разрываться', 'начнем', 'ебаться', 'счастье', 'казниться', 'решилась соблазниться'], ['медленно сниму штаны', 'поцелуями сломлю твое сомненье', 'похоти войдешь', 'опьяненье', 'кончишь'], ['смазку принесу', 'почувствуешь прохладу', 'жарить', 'большой трубой', 'получу усладу'], ['напиши', 'приду', 'пощекочу твою пизду снутри', 'ибо', 'устанет'], ['покусаю твою попу', 'трахать', 'жопу', 'ментов', 'вызовут', 'вой той девки', 'кайфует подо'], ['сниму презерватив', 'мирамистином', 'полью', 'минут', 'перерыв ', 'час', 'бою'], ['шея', 'укусах', 'засосах', 'болеть', 'включая твою грудь', 'пару дней', 'тоскуя', 'вопросов', 'захочешь', 'ночь вернуть']]
# stem and lemmatize all words in all phrases
stemmed_phrases = phrases_transform ( char_phrases , func = stem_lem )
print2 ( stemmed_phrases )
# [['жоп шил', 'моч доста'], ['имет оп', 'да'], ['влагалищ тво', 'тонус привест'], ['писа адрес', 'прийт'], ['член', 'словн бана', 'крив', 'матк вплот', 'дно зайт', 'полчас стоя смогет', 'границ часов'], ['разрыва', 'нача', 'еба', 'счаст', 'казн', 'реш соблазн'], ['медлен снят штан', 'поцел слом тво сомнен', 'похот войт', 'опьянен', 'конч'], ['смазк принест', 'почувствова прохлад', 'жар', 'больш труб', 'получ услад'], ['написа', 'прийт', 'пощекота тво пизд снутерет', 'иб', 'уста'], ['покуса тво поп', 'траха', 'жоп', 'мент', 'вызва', 'во тот девк', 'кайфова под'], ['снят презерват', 'мирамистин', 'пол', 'минут', 'перер', 'час', 'бо'], ['ше', 'укус', 'засос', 'болет', 'включ тво груд', 'пар ден', 'тоскова', 'вопрос', 'захотет', 'ноч вернут']]
# convert each phrase to list of n-grams
n_grams = phrases_transform ( stemmed_phrases , func = lambda w : words_to_ngrams_list ( w . split (), n_min = 1 , n_max = 2 ))
print2 ( n_grams )
# [[['жоп', 'шил', 'жоп шил'], ['моч', 'доста', 'моч доста']], [['имет', 'оп', 'имет оп'], ['да']], [['влагалищ', 'тво', 'влагалищ тво'], ['тонус', 'привест', 'тонус привест']], [['писа', 'адрес', 'писа адрес'], ['прийт']], [['член'], ['словн', 'бана', 'словн бана'], ['крив'], ['матк', 'вплот', 'матк вплот'], ['дно', 'зайт', 'дно зайт'], ['полчас', 'стоя', 'смогет', 'полчас стоя', 'стоя смогет'], ['границ', 'часов', 'границ часов']], [['разрыва'], ['нача'], ['еба'], ['счаст'], ['казн'], ['реш', 'соблазн', 'реш соблазн']], [['медлен', 'снят', 'штан', 'медлен снят', 'снят штан'], ['поцел', 'слом', 'тво', 'сомнен', 'поцел слом', 'слом тво', 'тво сомнен'], ['похот', 'войт', 'похот войт'], ['опьянен'], ['конч']], [['смазк', 'принест', 'смазк принест'], ['почувствова', 'прохлад', 'почувствова прохлад'], ['жар'], ['больш', 'труб', 'больш труб'], ['получ', 'услад', 'получ услад']], [['написа'], ['прийт'], ['пощекота', 'тво', 'пизд', 'снутерет', 'пощекота тво', 'тво пизд', 'пизд снутерет'], ['иб'], ['уста']], [['покуса', 'тво', 'поп', 'покуса тво', 'тво поп'], ['траха'], ['жоп'], ['мент'], ['вызва'], ['во', 'тот', 'девк', 'во тот', 'тот девк'], ['кайфова', 'под', 'кайфова под']], [['снят', 'презерват', 'снят презерват'], ['мирамистин'], ['пол'], ['минут'], ['перер'], ['час'], ['бо']], [['ше'], ['укус'], ['засос'], ['болет'], ['включ', 'тво', 'груд', 'включ тво', 'тво груд'], ['пар', 'ден', 'пар ден'], ['тоскова'], ['вопрос'], ['захотет'], ['ноч', 'вернут', 'ноч вернут']]]
# convert list of list of list to just list
total = sum_phrases ( n_grams )
print2 ( total )
# ['жоп', 'шил', 'жоп шил', 'моч', 'доста', 'моч доста', 'имет', 'оп', 'имет оп', 'да', 'влагалищ', 'тво', 'влагалищ тво', 'тонус', 'привест', 'тонус привест', 'писа', 'адрес', 'писа адрес', 'прийт', 'член', 'словн', 'бана', 'словн бана', 'крив', 'матк', 'вплот', 'матк вплот', 'дно', 'зайт', 'дно зайт', 'полчас', 'стоя', 'смогет', 'полчас стоя', 'стоя смогет', 'границ', 'часов', 'границ часов', 'разрыва', 'нача', 'еба', 'счаст', 'казн', 'реш', 'соблазн', 'реш соблазн', 'медлен', 'снят', 'штан', 'медлен снят', 'снят штан', 'поцел', 'слом', 'тво', 'сомнен', 'поцел слом', 'слом тво', 'тво сомнен', 'похот', 'войт', 'похот войт', 'опьянен', 'конч', 'смазк', 'принест', 'смазк принест', 'почувствова', 'прохлад', 'почувствова прохлад', 'жар', 'больш', 'труб', 'больш труб', 'получ', 'услад', 'получ услад', 'написа', 'прийт', 'пощекота', 'тво', 'пизд', 'снутерет', 'пощекота тво', 'тво пизд', 'пизд снутерет', 'иб', 'уста', 'покуса', 'тво', 'поп', 'покуса тво', 'тво поп', 'траха', 'жоп', 'мент', 'вызва', 'во', 'тот', 'девк', 'во тот', 'тот девк', 'кайфова', 'под', 'кайфова под', 'снят', 'презерват', 'снят презерват', 'мирамистин', 'пол', 'минут', 'перер', 'час', 'бо', 'ше', 'укус', 'засос', 'болет', 'включ', 'тво', 'груд', 'включ тво', 'тво груд', 'пар', 'ден', 'пар ден', 'тоскова', 'вопрос', 'захотет', 'ноч', 'вернут', 'ноч вернут']
# convert all objects to set
total_set = wordlist2set ( total , save_order = False )
print2 ( total_set )
# {'траха', 'влагалищ', 'больш труб', 'адрес', 'зайт', 'влагалищ тво', 'снят штан', 'вопрос', 'счаст', 'слом', 'груд тво', 'поцел слом', 'дно', 'опьянен', 'жоп', 'иб', 'труб', 'болет', 'тот', 'мирамистин', 'моч', 'поцел', 'доста моч', 'прохлад', 'мент', 'пощекота тво', 'укус', 'ден', 'кайфова', 'уста', 'войт похот', 'да', 'девк тот', 'во тот', 'вернут ноч', 'груд', 'границ часов', 'услад', 'засос', 'имет оп', 'презерват', 'стоя', 'принест', 'сомнен тво', 'пизд тво', 'покуса тво', 'разрыва', 'перер', 'оп', 'сомнен', 'соблазн', 'еба', 'крив', 'тонус', 'полчас стоя', 'жар', 'захотет', 'тоскова', 'смогет', 'вплот', 'писа', 'бо', 'пощекота', 'адрес писа', 'почувствова прохлад', 'медлен', 'снят', 'вызва', 'кайфова под', 'ноч', 'получ услад', 'во', 'прийт', 'пар', 'член', 'минут', 'похот', 'медлен снят', 'казн', 'написа', 'штан', 'включ тво', 'реш', 'войт', 'снутерет', 'покуса', 'ше', 'пол', 'девк', 'смогет стоя', 'час', 'пизд снутерет', 'конч', 'почувствова', 'жоп шил', 'доста', 'ден пар', 'включ', 'часов', 'привест тонус', 'слом тво', 'дно зайт', 'пизд', 'смазк', 'вернут', 'словн', 'больш', 'презерват снят', 'бана словн', 'имет', 'тво', 'вплот матк', 'принест смазк', 'шил', 'полчас', 'поп тво', 'под', 'поп', 'бана', 'матк', 'нача', 'реш соблазн', 'границ', 'получ', 'привест'}
# all these steps are equal to pipeline
pipe = StemLemPipeline ([
text2sentences , phrases2lower ,
lambda sentences : list ( map ( lambda s : sentence_split ( s , separators = ',;' , stop_words = stopwords ( 'ru' )), sentences )),
lambda p : phrases_without_excess_symbols ( p , include_alpha = True , include_numbers = True ),
lambda p : phrases_transform ( p , stem_lem ),
lambda p : phrases_transform ( p , func = lambda w : words_to_ngrams_list ( w . split (), n_min = 1 , n_max = 2 )),
sum_phrases ,
lambda p : wordlist2set ( p , save_order = False )
])
pipe ( text_example )
print ( total_set == pipe ( text_example )) # True هل من الضروري إجراء العديد من الانقسامات ، والترشيح والنزول؟ .. لماذا لا يمكننا استخدام التعبيرات العادية فقط؟ أعتقد أنه يجب علينا دائمًا فعل المزيد لإزالة المعلومات غير الضرورية والمهندس معلومات أفضل من البيانات النصية. على سبيل المثال:
, ; ? ! . ويجب أن نقسم الجمل بواسطة هذه الكائنات أيضًا قبل إنشاء n-grams يوجد تحت بعض التعليمات كيفية القيام بهذه المنطق باستخدام StemLemPipe
هناك العديد من الوظائف لتقسيم النص إلى قائمة الأوتار باستخدام منطق مختلف:
text2sentences(txt, equal_to_space = ["n"])split_by_words(sentence, words)sentence_split(sentence, separators = ",;!?", stop_words = None)انظر مثال على استخدام
استخدم text2sectences لتقسيم النص إلى قائمة الجمل.
بعد الاستعدادات السابقة ، لدينا قائمة بالجمل حيث تكون كل جملة سلسلة أو قائمة بالسلسلة. لتطبيق بعض الوظائف على الأوتار في هذا البناء ، هناك وظيفة phrases_transform(phrases, func, progress_bar = False) حيث تكون func هي الوظيفة التي تنطبق على كل سلسلة. هناك أيضًا بعض أغلفة phrases_transform لبعض المهام:
phrases2lower(phrases)phrases_without_excess_symbols(phrases, include_alpha = True, include_numbers = False, include_also = None)انظر مثال على استخدام
لهذا ، يمكنك استخدام وظائف sentence_split أو split_by_words من الكتلة السابقة.
استخدم وظيفة stopwords(language = 'ru') للحصول على كلمات إيقاف ، ولكن يمكنك استخدام كلمات التوقف الخاصة بك أيضًا!
لتطبيق ترجمة التنقيب للعبارات u يجب أن تنشئ بعض وظيفة lemmatization واستخدامها إذا مع phrases_transform . إنشاء وظيفة lemmatization بإحدى الطرق:
create_lemmatizer(backend = 'pymorphy', language = 'ru')create_stemmer(backend = 'snowball', language = 'ru')create_stemmer_lemmer(lemmatizer_backend = 'pymorphy', stemmer_backend = 'snowball', language = 'ru') - خط أنابيب مع lemmatizer و stemmertext -> textمتاحون من الجذعية :
| لغة | الخلفية |
|---|---|
'ru' | 'snowball' |
'en' | 'snowball' |
متوفرات متوفرة :
| لغة | الخلفية |
|---|---|
'ru' | 'pymorphy' ، 'mystem' |
'en' | 'wordnet' |
ليس من الصعب إضافة lemmatizizers جديدة ولكن فقط أخبرني بذلك. إلقاء نظرة على الملف المصدر
طرق للحصول على n-grams من مجموعة من الكلمات :
get_ngrams(arr, n=2)words_to_ngrams_list(words, n_min = 1, n_max = 2)كيفية استخدام:
from StemLemPipe import get_ngrams , words_to_ngrams_list
text = "word1 word2 word3 ... word10"
# returns generator
gen = get_ngrams ( text . split (), n = 3 )
# just list of lists
print ( list ( gen ))
# [['word1', 'word2', 'word3'], ['word2', 'word3', '...'], ['word3', '...', 'word10']]
# words in n-gram are combined, it's list of strings
print ( words_to_ngrams_list ( text . split (), n_min = 1 , n_max = 3 ))
# ['word1', 'word2', 'word3', '...', 'word10', 'word1 word2', 'word2 word3', 'word3 ...', '... word10', 'word1 word2 word3', 'word2 word3 ...', 'word3 ... word10'] يمكننا تحويل قوائم قوائم القوائم ... إلى قائمة السلاسل باستخدام وظيفة sum_phrases . كما يمكننا تحويل هذه القائمة من السلاسل لتعيينها باستخدام وظيفة wordlist2set(input_list, save_order = False) هناك save_order = True تعني أن n-grams مثل word1 word2 و word2 word1 ليست (نفس خلاف ذلك).
قم بإنشاء كائن StemLemPipeline لاستخدام وظائف معينة واحدة تلو الأخرى للنصوص الجديدة.
إنشاء خط أنابيب باستخدام الكود:
from StemLemPipe import StemLemPipeline
pipe = StemLemPipeline ([ func1 , func2 , ...])لاستخدام خط الأنابيب فقط اتصل:
result = pipe ( 'some text for preparations' )وهو يدعم المقاييس التالية:
Levenstein.usual(str1, str2)Levenstein.deep(s1, s2, remove_desc = True)لإعداد النص ، قد يكون من المفيد للغاية استخدام الوظائف التالية:
remove_words(text, words) - فقط يزيل الكلمات التالية من النص دون الانقسام إلى العبارات (على عكس sentence_split )remove_hook_words(text, hook_words) - يزيل الكلمات الخطاف من النص بكلمة واحدة التالية. بالنسبة إلى text = "abcdef" و hook_words = ['b', 'e'] إرجاع "ad" (بدون الكلمات b ، e والكلمات التالية) (مثال)

