easy speech
v2.4.0
مستندات API »
تم إنشاء هذا المشروع ، لأنه دائمًا ما يكون صراعًا للحصول على جزء من توليف Web Speech API يعمل على معظم المتصفحات الرئيسية.
speechSynthesis عبر متصفحات متعددةEasySpeech.debugملاحظة: هذه ليست حزمة polyfill ، إذا لم يدعم متصفحك المستهدف تخليق الكلام أو واجهة برمجة تطبيقات خطاب الويب ، فإن هذه الحزمة غير قابلة للاستخدام.
يتوفر العرض التوضيحي المباشر على https://leaonline.github.io/asy-speech/ يمكنك استخدامه لاختبار متصفحك لدعم ووظائف speechSynthesis .
جدول المحتويات المتولدة مع الدكتوراه
تثبيت من NPM عبر
$ npm install easy-speech يمكنك أيضًا استخدام التصميمات المختلفة لأهداف مختلفة ، انظر مجلد dist :
/dist/EasySpeech.js - esm/dist/EasySpeech.cjs.js - commonjs/dist/EasySpeech.es5.js - العقدة القديمة متوافقة/dist/EasySpeech.iife.js - بناء متوافق مع Legacy ، يعمل حتى مع المتصفحات القديمة أو الغريبة ، طالما أنها تدعم الوعود (مرحبًا بك في التحويل إلى عمليات الاسترجاعات!)/dist/index.d.ts - تعريفات نوع TypeScriptيمكنك استخدامها عبر CDN:
<!-- esm -->
< script type =" module " >
import easySpeech from 'https://cdn.jsdelivr.net/npm/easy-speech/+esm'
</ script > <!-- classic -->
< script src =" https://cdn.jsdelivr.net/npm/easy-speech/dist/EasySpeech.iife.js " > </ script > استيراد EasySpeech والأول ، اكتشف ، إذا كان متصفحك قادرًا على TTS (نص إلى الكلام):
import EasySpeech from 'easy-speech'
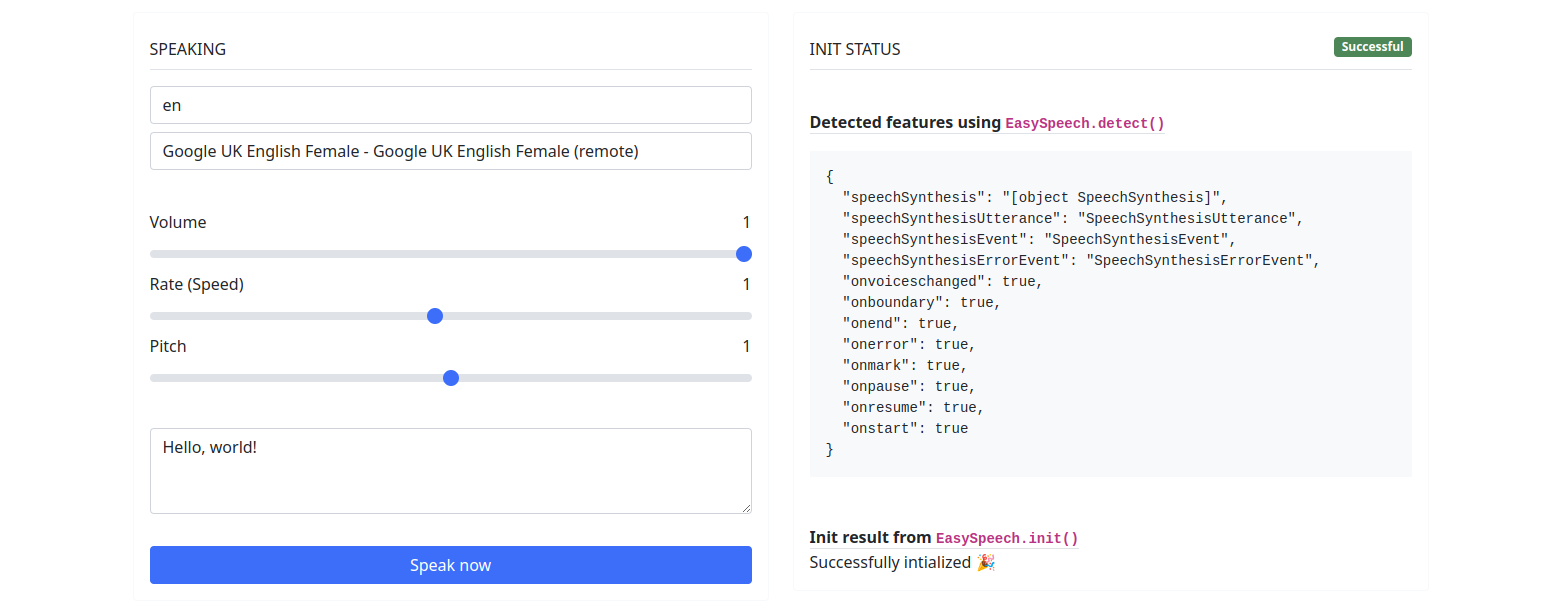
EasySpeech . detect ( )يعيد كائن بالمعلومات التالية:
{
speechSynthesis : SpeechSynthesis | undefined ,
speechSynthesisUtterance : SpeechSynthesisUtterance | undefined ,
speechSynthesisVoice : SpeechSynthesisVoice | undefined ,
speechSynthesisEvent : SpeechSynthesisEvent | undefined ,
speechSynthesisErrorEvent : SpeechSynthesisErrorEvent | undefined ,
onvoiceschanged : Boolean ,
onboundary : Boolean ,
onend : Boolean ,
onerror : Boolean ,
onmark : Boolean ,
onpause : Boolean ,
onresume : Boolean ,
onstart : Boolean
} إذا تم تحديد على الأقل SpeechSynthesis SpeechSynthesisUtterance ، فقد تم تحديدك على الأقل ، فأنت على ما يرام.
إن إعداد كل شيء للعمل ليس واضحًا كما ينبغي ، خاصة عند استهداف وظائف المتصفح. ستساعدك وظيفة init غير المتزامنة في هذا الموقف:
EasySpeech . init ( { maxTimeout : 5000 , interval : 250 } )
. then ( ( ) => console . debug ( 'load complete' ) )
. catch ( e => console . error ( e ) ) سوف يمر init-routine بعدة مراحل لإعداد البيئة:
onvoiceschanged : استخدم onvoiceschangedonvoiceschanged متاحًا: احتياطي إلى مهلةonvoiceschanged ولكن لا توجد أصوات متاحة: العودة إلى المهلةinterval معينة حتى يتم الوصول إلى maxTimeoutإذا لم يتم اكتشاف توجيه init الخاص بك / تحميل أي أصوات ، فسيتم دعم All BeableSenth ، فيرجى ترك مشكلة!
إذا تم العثور على الأصوات ، فسوف يضع صوتًا احتياطيًا وفقًا للقواعد التالية:
default على True ، فاستخدم هذا كصوت احتياطيnavigator.language ملاحظة: لا يتم التغلب على صوت الاحتياطي هذا بواسطة EasySpeech.defaults() ، سيتم استخدام صوتك الافتراضي لصالح ولكن صوت الاحتياط سيكون دائمًا في حالة عدم العثور على صوت عند استدعاء EasySpeech.speak()
هذا سهل كما يحصل:
await EasySpeech . speak ( {
text : 'Hello, world!' ,
voice : myLangVoice , // optional, will use a default or fallback
pitch : 1 ,
rate : 1 ,
volume : 1 ,
// there are more events, see the API for supported events
boundary : e => console . debug ( 'boundary reached' )
} ) سيتم حل الوعد تلقائيًا عند انتهاء التحدث أو يرفض عند حدوث خطأ. يمكنك أيضًا إرفاق مستمعي الأحداث هؤلاء إذا أردت أو تستخدم EasySpeech.on لإرفاق المستمعين الافتراضيين في كل مرة تتصل فيها EasySpeech.speak .
هناك قسم أسئلة وأجوبة خاصة يهدف إلى المساعدة في القضايا المشتركة.
تتوفر وثائق API كاملة: مستندات API
يتم الترحيب بكل مساهمة ، يرجى فتح المشكلات إذا كان أي شيء لا يعمل كما هو متوقع.
إذا كنت تنوي المساهمة في الكود ، فيرجى قراءة الإرشادات حول المساهمة.
استخدم هذا المشروع العديد من الموارد لاكتساب رؤى حول كيفية الحصول على أفضل خطاب المتصفح المتقاطع:
معهد ماساتشوستس للتكنولوجيا ، انظر ملف الترخيص


